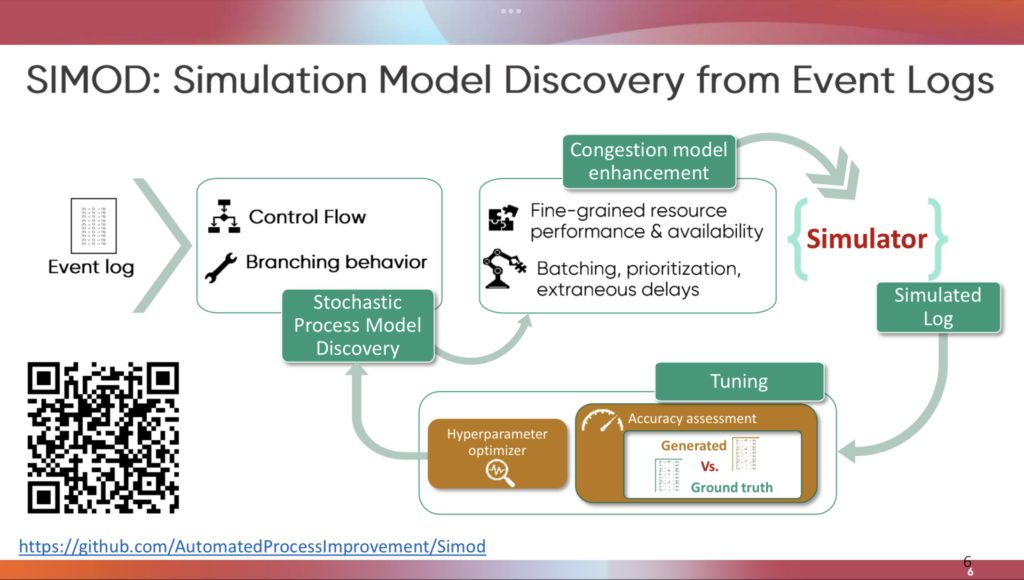
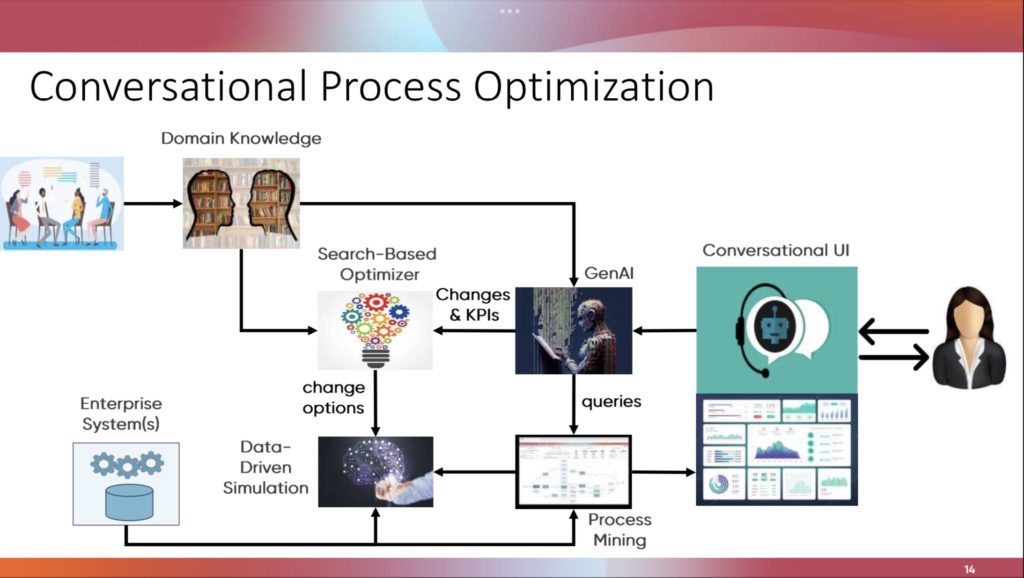
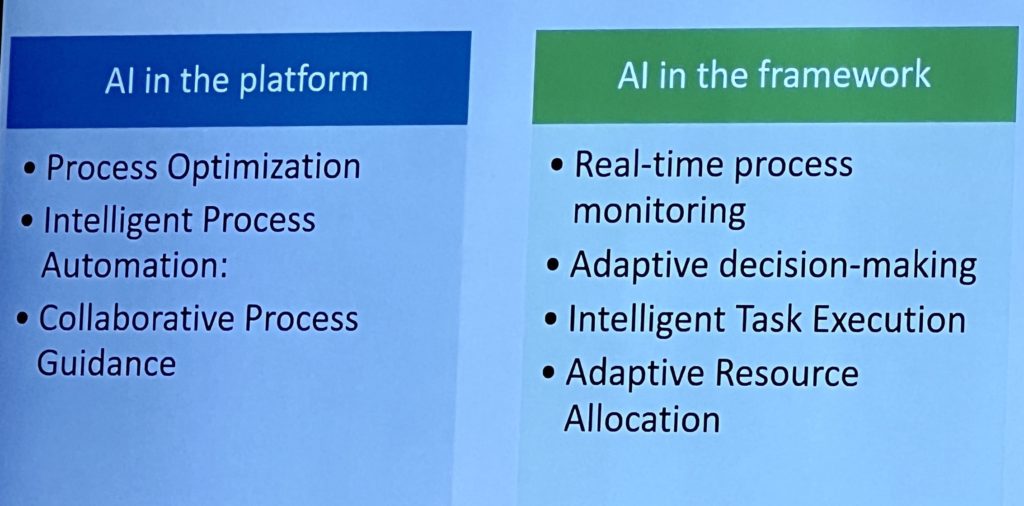
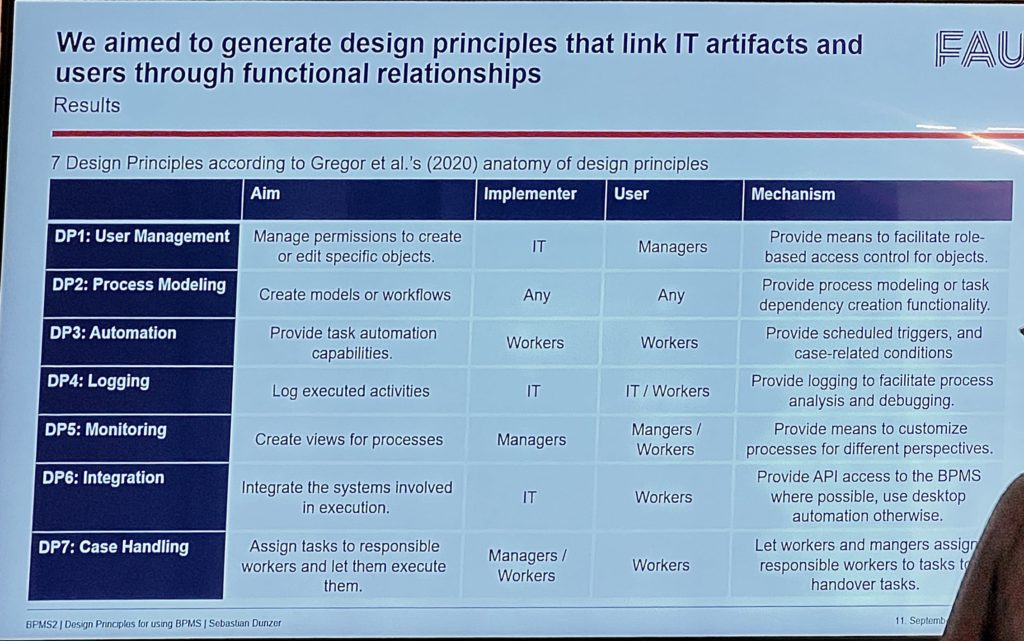
We’ve started the breakout paper presentations and I’m in the session on design patterns and modeling. For these breakouts, I’ll mostly just offer a few notes since it’s difficult to get an in-depth sense in such a short time. I’ll provide the paper and author names in case you want to investigate further. Note that some of the images that I include are screenshots from the conference proceedings: although the same information was shown in the presentations, the screenshots are much more legible than my photos made during the presentations.
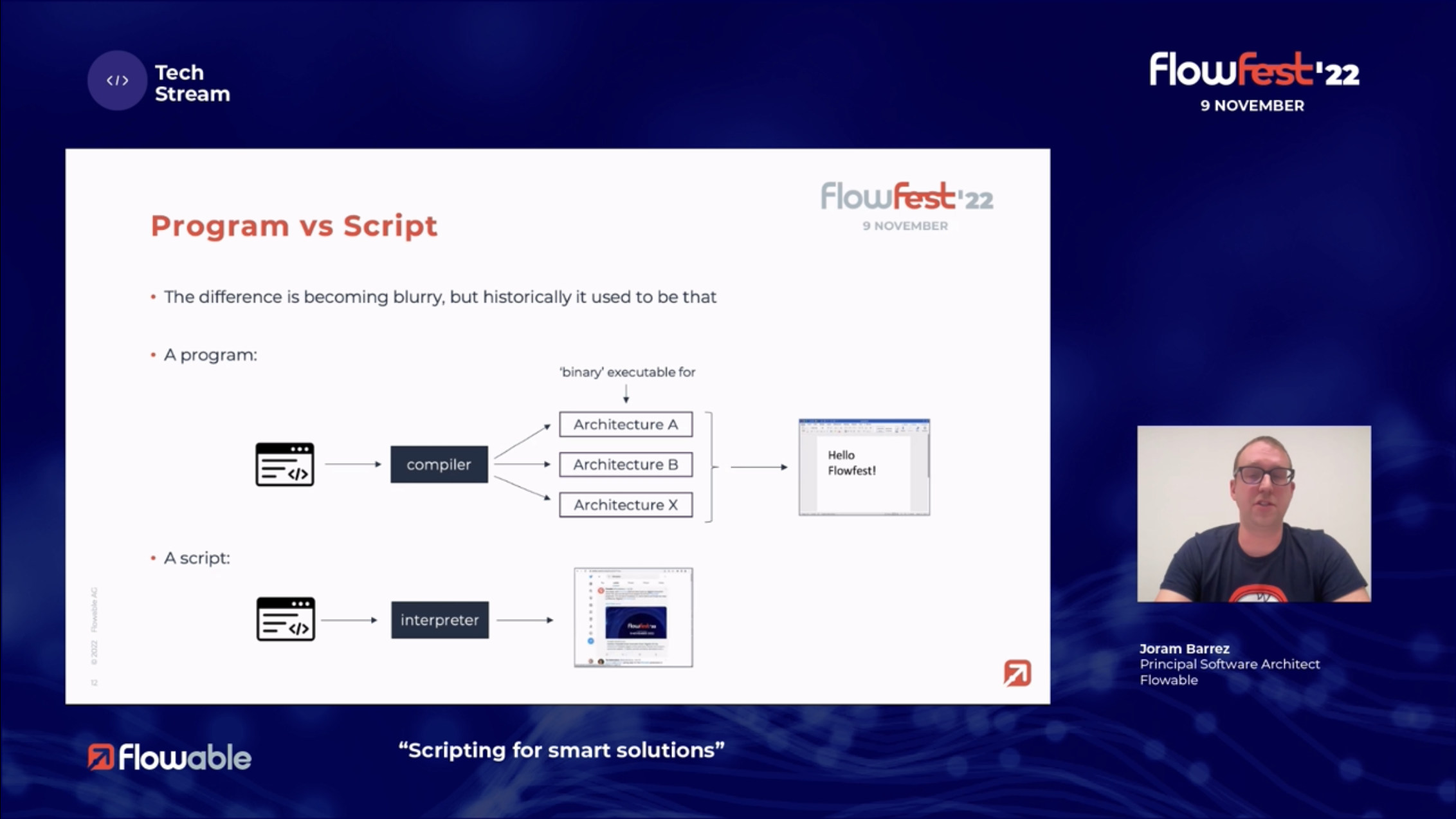
The first paper is “Not Here, But There: Human Resource Allocation Patterns” (Kanika Goel, Tobias Fehrer, Maximilian Röglinger, and Moe Thandar Wynn), presented by Tobias Fehrer. Patterns help to document BPM best practices, and they are creating a set of patterns specifically for human resource allocation within processes. They did a broad literature review and analysis to distill out 15 patterns, then evaluated and refined these through interviews with process improvement specialists to determine usefulness and pervasiveness. The resulting patterns fall into five categories: capability (expertise, role, preference), utilization (workload, execution constraints), reorganization (empower individual workers to make decisions to avoid bottlenecks), productivity (efficiency/quality based on historical data), and collaboration (based on historical interactions within teams or with external resources). This is a really important topic in human tasks within processes: just giving the same work to the same person/role all the time isn’t necessarily the best way to go about it. Their paper summarizes the patterns and their usefulness and pervasiveness measures, and also considers human factors such as the well-being and “happiness” of the process participants, and identifying opportunities for upskilling. Although he said explicitly that this is intended for a priori process design, there’s likely knowledge that can also be applied to dynamic runtime resource allocation.
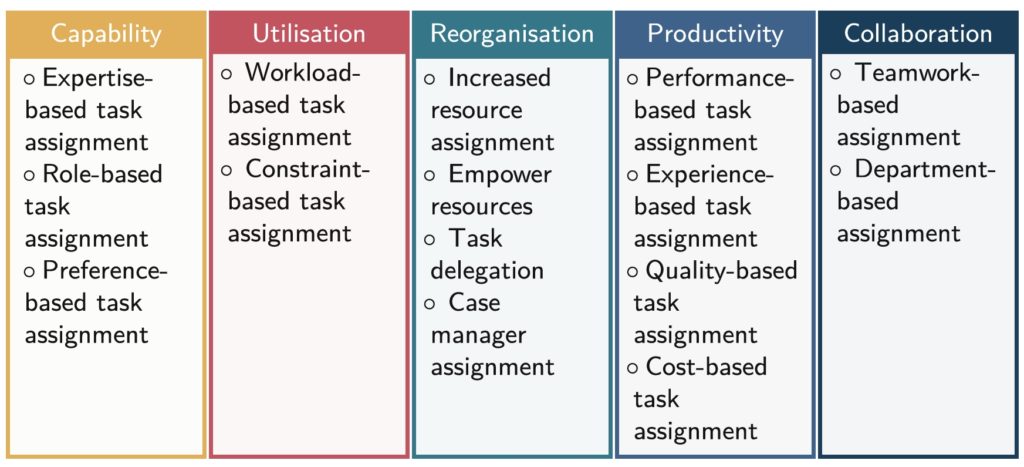
The second presentation was “POWL: Partially Ordered Workflow Language” (Humam Kourani and Sebastiaan van Zelst), presented by Humam Kourani. He introduced their new modeling language, POWL, that allows for a better discovery and representation of partial orders, that is, where some activities have a strict order, while others may happen in any order. This is fairly typically in semi-structured case management, where there can be a combination of sets of tasks that can be performed in any order plus some predefined process segments.
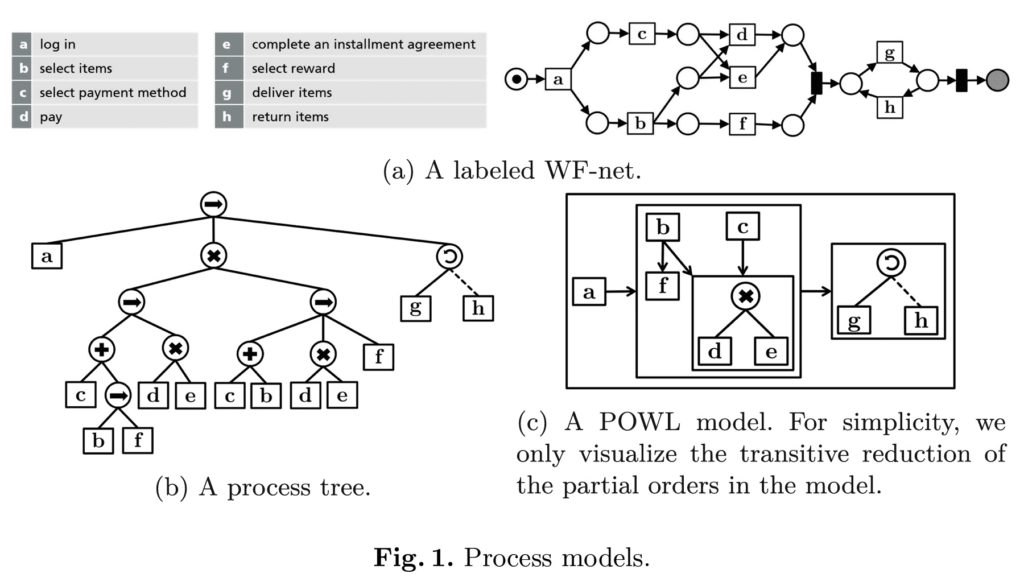
The third presentation was “Benevolent Business Processes – Design Guidelines Beyond Transactional Value” (Michael Rosemann, Wasana Bandara, Nadine Ostern, and Marleen Voss), presented by Michael Rosemann. Benevolent processes consider the needs of the customer as being as important as (or even more important) the needs of the “provider”, that is, the organization that owns the process. BPM has historically been about improving efficiency, but many are looking at other metrics such as customer satisfaction. In my own writing and presentations, I make an explicit link between customer satisfaction and high-level revenue/cost metrics, and the concept of benevolent processes fits well with that. Benevolence goes beyond customer-centric process design to provide an immediate, unexpected and optional benefit to the recipient. A thought-provoking view on designing processes that will create fiercely loyal customers.
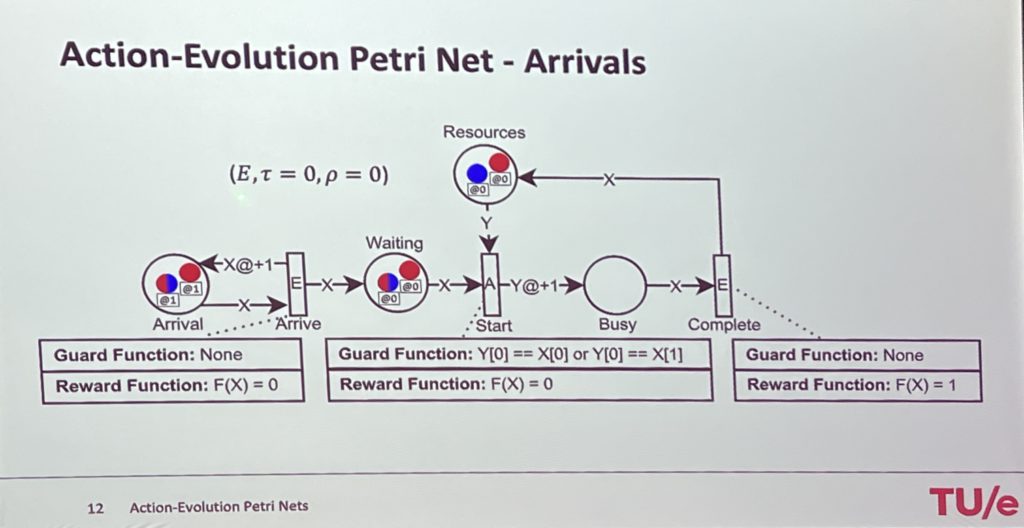
The final presentation in this session was “Action-Evolution Petri Nets: a Framework for Modeling and Solving Dynamic Task Assignment Problems” (Riccardo Lo Bianco, Remco Dijkman, Wim Nuijten, and Willem Van Jaarsveld), presented by Riccardo Lo Bianco. Petri nets have no mechanisms for calculating assignment decisions, so their work looks at how to model task assignment that attempts to optimize that assignment. For example, if there are two types of tasks and two resources, where one resource can only perform one type of task, and another resource can perform either type of task, how is the work best assigned? A standard assignment would just randomly assign tasks to resources, filtered by resource capability, but that may result in poor results depending on the composition of the tasks waiting in the queue. They have developed and shared a framework for modeling and solving dynamic task assignment problems.
Good start to the breakout sessions, and excellent insights on some difficult process modeling research problems.