Judith Morley presented on their new case management capability; she started from some pretty basic principles explaining knowledge work, so likely a fairly novel capability for most of the audience.
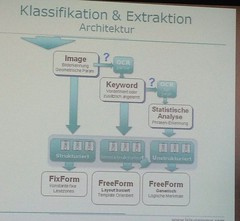
She described case management as a new application or user interface, meaning that the AWD 10 BPM capabilities are there as part of it, but it has additional capabilities such as collaboration, content, ad hoc processes and deadlines. This circles back around the ongoing discussions in the industry about the relationship between BPM and ACM; certainly, process is a part of ACM (even structured process), but it’s more than that. They did research with their own BPO companies and some of their customers spanning retirement, mutual funds, insurance and healthcare industries, and came up with four design imperatives for a case management solution:
- A humane way of working with files
- Reorienting yourself to a case: making it easy to pick up where you left off after some time away from the case
- Immediate responsibility versus ultimate responsibility: understanding ownership and responsibility for meeting milestones
- A system that suggests rather than dictates: supporting the knowledge worker rather than enforcing a specific process
The primary workspace now for knowledge workers (as defined in their profile) is a dashboard listing their top 10 tasks – as defined by what they own and due date – and a task forecast for the next three weeks, then their top 10 cases and the case workload of all members of the worker’s team. There are two other tabs for cases and tasks; on each of those are interactive filtered views of the cases and tasks in progress. Both cases and tasks are types of AWD work items (with a predefined process model, even if just a single-step user task), with tasks being children of cases; opening a case or a task takes you to a view of that work item with the related data, content and activity. Tasks can be added to a case by the worker, using a template, and content can be added at the case or task level. Messages get passed around between cases and their tasks to allow for processes to be started, paused and rendezvoused appropriately. Cases can be created from templates as well, where a case template contains one or more tasks of any degree of complexity. Both task and case templates are, in fact, templates: if they are changed, work that is already instantiated is not impacted. Furthermore, cases can be organized into folders as a collection mechanism, although folders are not routes as cases and tasks are.
This is not yet a released product: it’s scheduled for the end of 2012 or the beginning of 2013, and they are currently researching different representations that they might create of manager and team views, as well as reporting on knowledge work. This latter issue is one that I’ve been talking about a bit lately, and proposed it as one of the “unanswered questions” in my presentation on the nature of work at last year’s academic BPM conference.