Camunda co-founder Bernd Rücker presented on some of the implementation issues with microservices, in particular following on from Susanne Kaiser’s keynote with the theme of having small delivery teams spend more of their time developing business capabilities and less on the “undifferentiated heavy lifting” infrastructure bits required to support those. This significantly reduces the cognitive load for the team, allowing them to build the best possible business capabilities without worrying about arcane configuration details. Interestingly, this is not that different from the argument to move from a business process embedded within a business system logic to an externalized process in a BPMS — something that Bernd has a long history with.
He went through an example of the services behind a train ticket booking, which requires payment, seat reservation and ticket generation services; there are issues of latency and uptime as well as the user experience of how the results of those services are presented to the customer. He referenced the Reactive Manifesto as a guideline for software design patterns that are “more robust, more resilient, more flexible and better positioned to meet modern demands”.
Event-driven choreography is a common pattern these days, but has the problem of not being able to visualize the overall process flow between services. This can be alleviated somewhat by using event monitoring overlaid on a process model — effectively process discovery if the flow is not standardized or when it changes — or even more so by orchestrating standard parts of the flow to combine event-driven and orchestration patterns. Orchestration has the advantage of relocating the coupling between services in an event-driven flow to the orchestration layer: although event choreography is seen as loosely-coupled, there’s a lot of event listening that has to be built into the services, which couples them more closely. It’s not that one is good and the other bad: there’s a place for both choreography and choreography patterns in software development.
He finished with a discussion of monolithic legacy software and how to deal with it: from the initial step of just adding APIs to access functionality, you gradually chip away at the monolith’s capabilities, ripping them out replacing with externalized services.
Susanne Kaiser, former CTO of Just Social and now an independent technology consultant, opened the second day of CamundaCon 2019 with a presentation on moving to a microservices architecture, particularly for a small team. Similar to the message in my presentation yesterday, she advises building the processes that are your competitive differentiator, then outsourcing the rest to external vendors.
She walked through some of the things to consider when designing microservices, such as the ideas of bounded context, local data persistence, API discovery and management, linkage with message brokers, and more. There’s a lot of infrastructure complexities in building a single microservice, which makes it particularly challenging for small teams/companies — that’s part of what drives her recommendation to outsource anything that’s not a competitive differentiator.
Susanne Kaiser and the complexities of building a single microservice
She showed the use of Wardley maps for the evolution of a value chain, showing how components are mapped relative to their visibility to users and their level of maturity. Components of a solution/system are first identified by their visibility, usually in a top-down manner based on the functional requirements. They are then plotted along the evolution axis, to identify which will be custom-built versus those that are third-party products or outsourced commodities/utilities. This includes identifying all of the infrastructure to support those components; initially, this may include a lot of the infrastructure components as requiring custom build, but use of third-party products (including open source) can shift many of these components along the evolution axis.
Sample Wardley Map development for a solution (mid-evolution)
She then showed how Camunda BPM would fit into this map of the solution, and how it can abstract away some of the activities and components that were previously explicit. In short, Camunda BPM is a higher-level piece of infrastructure that can handle service orchestration including complexities of retries and more. I haven’t worked with Wardley Maps previously, and there are definitely some good concepts in here for helping to identify buy versus build components in a technical architecture.
Derek Vandivere of ING Netherlands finished up the first day of CamundaCon 2019 here in Berlin taking about how they moved from a regional to global platform migration — strange, because he’s actually talking about their Pega implementation although they’re also implementing Camunda — and how to work around the monoliths. I know that Derek’s wife is an art restorer, and this has obvious rubbed off on him since all of his slides were photos of Dutch Masters paintings that were (however peripherally) related to his subject matter.
Different ING regional operations selected different BPM engines: the Netherlands went with Pega, while Germany went with Camunda, with other areas building their own thing or using legacy TIBCO. They’re attempting to build some standards around how people talk about BPM and case management internally, as well as how applications are developed. As a global bank, they need to have some data, rules and processes that span countries, making it necessary to consider how to bring all of these disparate systems together.
Derek Vandivere discusses the challenges of having multiple vendors’ BPMS
He went through a number of the best practices and lessons learned that they discovered along the way as they rolled out a regional solution globally. Although his experience with the Dutch implementation was based on Pega, there are many transferrable lessons here, since a lot of it is about higher-level architecture, bottlenecks in processes and decision-making (often human bottlenecks, although some technical as well), and how to interact with the business areas.
He discussed with the current pressures on their monolithic iBPMS (Pega) platform that echoed some of what I talked about this morning: proprietary developer training, container-based microservices architecture, and multiple distributed deployment models (support for both cloud and regionally-mandated on-premise). Replacing or upgrading any sufficient complex IT is going to be a challenging task, but doing that with a monolithic iBPMS is considerably more challenging than a more distributed microservices architecture.
We’re about to spill out onto the Spree-side patio here at Radialsystem V for a BBQ and well-deserved refreshments, so that’s it for my coverage of this first day at CamundaCon 2019. I’ll be back for a couple of sessions tomorrow morning before heading south to Bolzano for next week’s DecisionCamp.
Sowmya Raghunathan and Corinna Cohn presented on a claims intake implementation that uses BPMN and DMN in an interesting way: driving the intake forms used by a claims administrator when gathering first notice of loss (FNOL) information from a claimant. The idea is that the claims admin doesn’t need to have any information about the claim type, and the claimant doesn’t get asked any irrelevant questions, because the form always presents the next best question based on previous responses: a wizard-like model, but driven by BPMN and DMN.
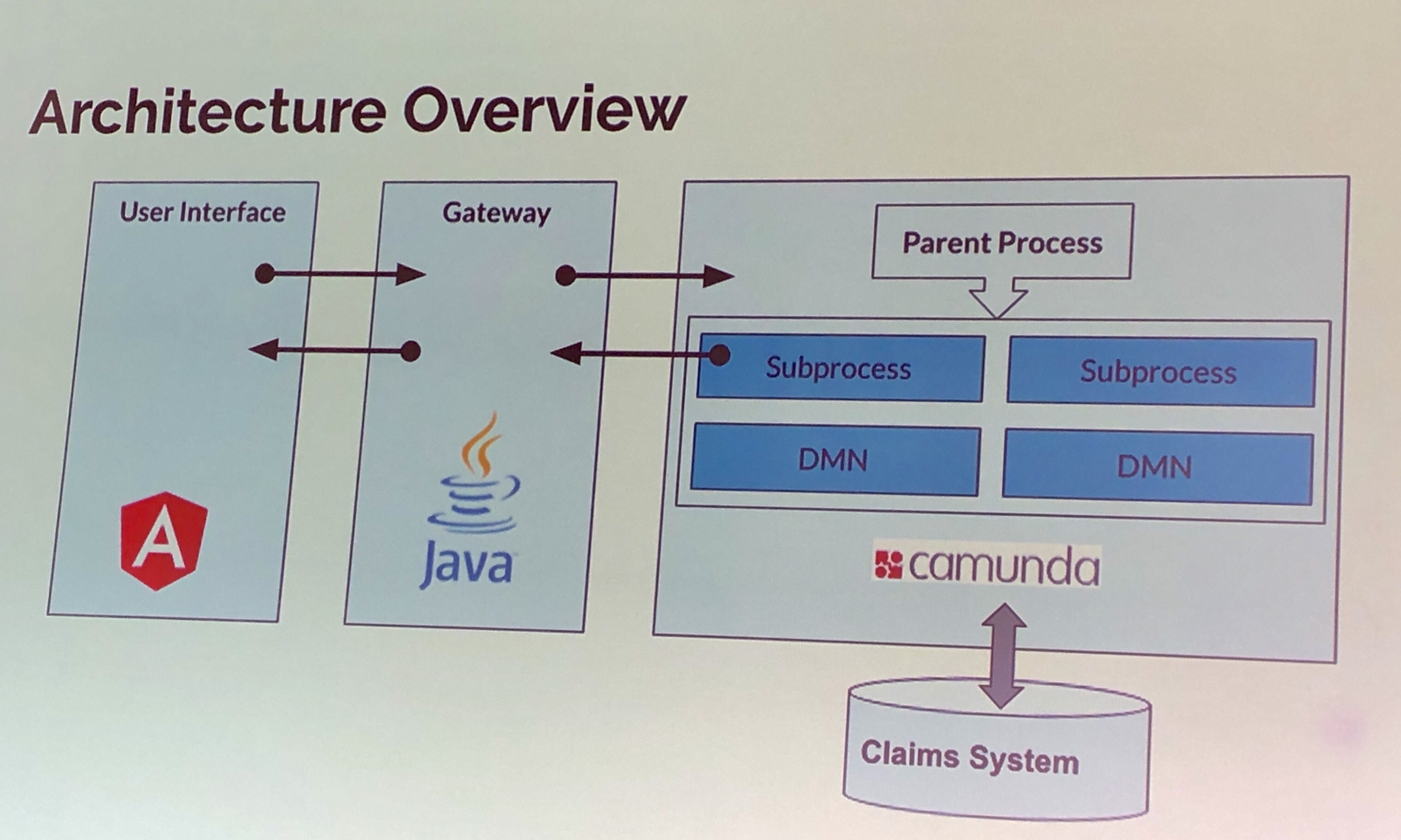
As the application and technical architects at Indiana Farm Bureau Insurance, they were able to give us a good view of how they use the tools for this: BPMN for orchestrating the DMN and UI communication as well as storing the responses, DMN for defining the questions and question/response mapping, and a UI component for implementing the survey forms. They consider this a headless application, but of course, it does surface via the form UI; from a Camunda process standpoint, however, it is decoupled piece of the architecture that interfaces with the claims system.
Technical architecture of the survey DMN/BPMN system
We saw a demo of one of the claim forms at work, where the previous questions and responses can be seen, and changes to the previous responses may cause changes to subsequent questions based on the DMN decision tables behind the scenes. They use a couple of DMN tables just as configuration tables for the UI for the questions and options (e.g., radio buttons versus free-form responses), then a Next Question decision table to determine the next question based on the previous response: this table is based on a directed acyclic graph that links questions (nodes) via answers (links), which allows for easy re-navigation of the graph if an earlier response is changed.
DMN decision table for FNOL questions related to auto claim
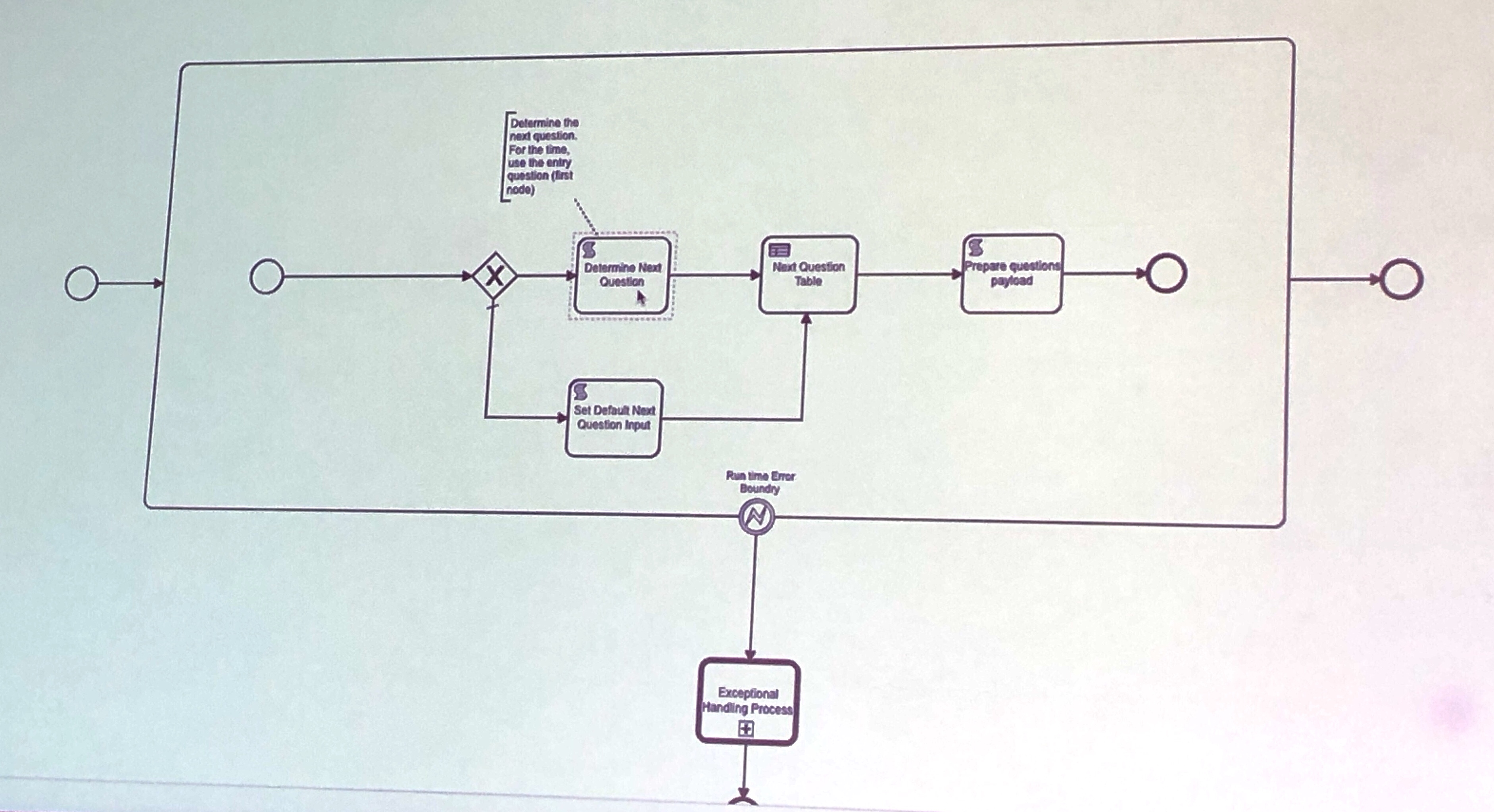
BPMN is used to navigate and determine the next question in a dynamic question subprocess, and if the survey can be exited; once sufficient information has been collected, the FNOL is initiated in the claims systems.
Dynamic Questions BPMN subprocess
The use of DMN means that the questions can be changed very easily since they’re not embedded in the code; this means that they can be created and modified by business analysts rather than requiring developers to code these into the UI directly.
FNOL BPMN process
The entire framework is reusable, and could be quickly reconfigured to be used for any type of survey. That’s great, because a few years ago, I saw a very similar use case for this in a clinical situation for a stroke assessment questionnaire: in a hospital setting, when someone arrives at an emergency department and is suspected of having had a stroke, there are standard questions to ask in order to evaluate the patient’s condition. At the time, I thought that this would be a perfect use case for DMN and BPMN, although that was beyond the scope of the project at that time.
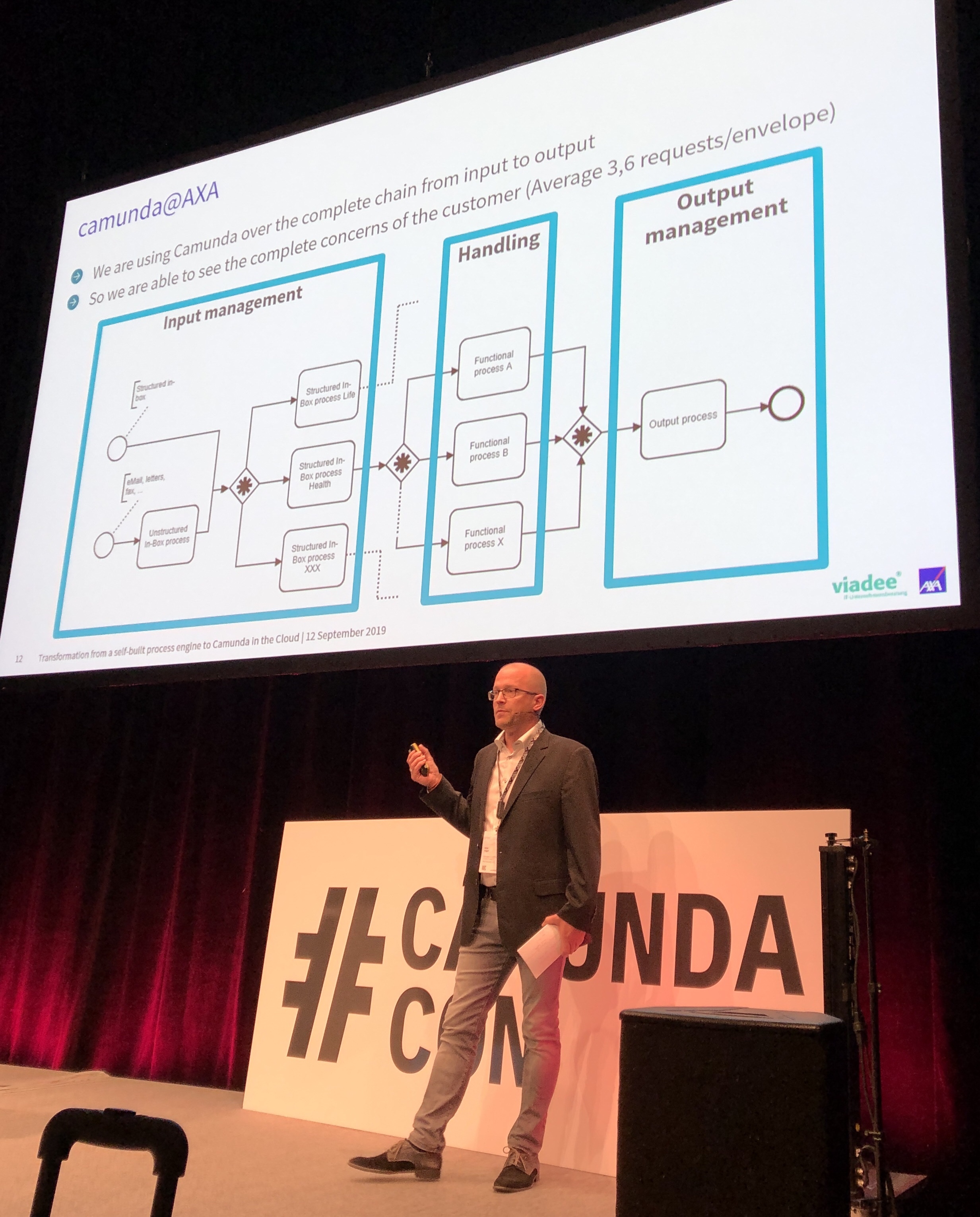
Niko Vogel of AXA Germany and Matthias Schulte of their consulting partner viadee presented on AXA’s journey from a process engine that they built in-house to a Camunda cloud-based process engine. This was driven by their move to a new policy management system, with the goal to automate as much as possible of their end-to-end travel and health insurance process, and support the knowledge workers for the human tasks.
They’ve seen a huge change in how business and IT work together: collaborating over process optimization and troubleshooting, for example. They have a central team for more of the infrastructure issues such as reporting and security, as well as acting as a center of excellence for BPMN and DMN.
Niko Vogel of AXA discussing how they use Camunda
They have made some extensions to Camunda’s Cockpit dashboard to tie in more business information, allowing business users to access it directly for looking up specific policy-related processes and see what’s happening with them. They’ve also done a “DMN Manager” extension to control the modification and deployment of decision tables, although changes to decision tables can still be done by the business without involvement from IT. Another significant extension is to collect runtime statistics from Camunda and other line-of-business systems to do some analysis on the aggregate; based on something that we saw in Daniel’s keynote this morning, this capability may soon be something offered directly by Camunda.
Their architecture started as a “shared monolith” in 2017, that is, a central deployment of a single Camunda server instance used by all process applications — note that this is the primary deployment model for many BPMS. They felt this was a good first step, but moved to a decentralized Spring Boot architecture to create decentralized standalone applications, although common tools remained in a shared instance.
Now, they’re moving to the cloud, which allows reuse of their existing service access architecture (integrating with policy administration system, for example) via tunneling in a very similar way as they used with the on-premise Spring Boot implementation. The current point of discussion is about how many databases to use: they are likely to move from their current centralized database to a less centralized model. This will give them much better elastic scalability and performance — a common database is a classic chokepoint when scaling — although this will require some definite rework to determine how to split up the databases and how to handle cross-application reporting in a transparent fashion.
Good questions and discussion with the audience at the end, including managing their large process model as it moves through business-IT collaboration to deployment.
Always a relief to present early so that I can focus on other presentations later in a conference. That being said, I didn’t get the chance to write about either Jakob Freund’s or Daniel Meyer’s presentations that bracketed mine: as CEO and CTO, they had some great stuff to talk about.
You can find my presentation slides below, and I understand there will be a YouTube video uploaded after the conference at some point. On to the rest of the conference!
To finish up my time at the academic research BPM 2019 conference, I attended one of the industry forum sessions, which highlights initiatives that bring together academic research and practical applications in industry. These are shorter presentations than the research sessions, although still have formal published papers documenting their research and findings; check those proceedings for the full author list for each paper and the details of the research.
Process Improvement Benefits Realization: Insights from an Australian University. Wasana Bandara, QUT
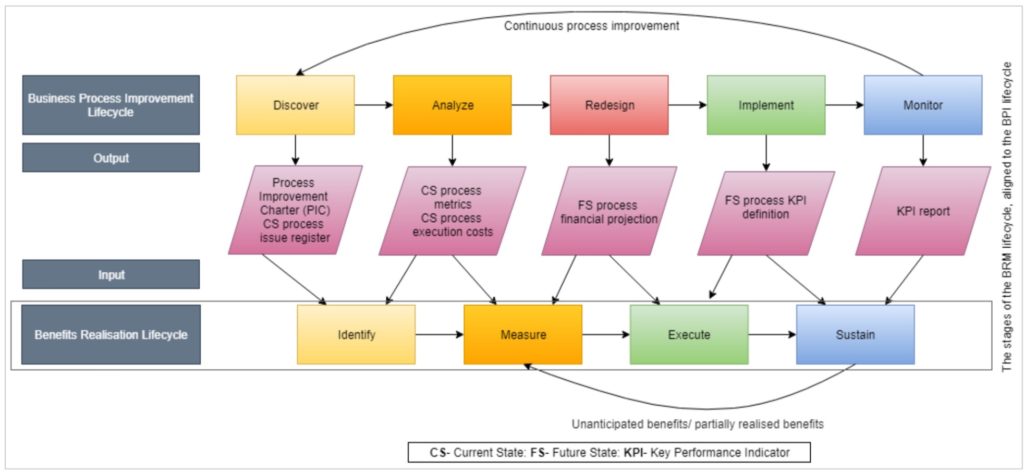
The first presentation was about process improvement at the author’s university. They took on an enterprise business process improvement project in 2017, and have developed a Business Process Improvement Office (BPIO — aka centre of excellence). They wanted to be able to have measurable benefits, and created a benefits realization framework that ran in parallel with their process improvement lifecycle to have the idea and measurement of benefits built in from the beginning of any project.
They found that identifying and aligning the ideas of benefits realization early in a project created awareness and increased receptiveness to unexpected benefits. Good discussion following on the details of their framework and how it impacts the business areas as they move their manual processes to more automation and management.
Enabling Process Mining in Aircraft Manufacture: Extracting Event Logs and Discovering Processes from Complex Data. Maria Teresa Gómez López, Universidad de Sevilla
The second presentation was about using process mining to discover the processes used in aircraft manufacture. The data underlying the process mining is generated by IoT manufacturing devices, hence had much higher volumes than a usual business process mining application, requiring preprocessing to aggregate the raw log data into events suitable for process mining. They also wanted to be able to integrate knowledge from engineers involved in the manufacturing process to capture best practices and help extract the right data from the raw data logs.
They had some issues with analyzing the log data, such as incorrect data (an aircraft was in two stations at the same time, or was moving backwards through the assembly process), incomplete or insufficient information. Future research and work on this will include potential integration with big data architectures to handle the volume of raw log data, and and finding new ways of analyzing the log data to have cleaner input to the process discovery algorithms.
The adoption of globally unified process standards via a multilingual management system The case of Marabu, a worldwide manufacturer of printing inks and creative colours of the highest quality. Klaus Cee, Marabu, and Andreas Schachermeier, ConSense
The next presentation was about how Marabu, a printing ink company, standardized and aligned their multinational subsidiaries’ business processes with the parent company. This was not a research project per se, although ConSense is a spinoff consulting company from a university project several years ago, but a process and knowledge management implementation project. They had some particular challenges with developing uniform multi-lingual processes that could have local variants, integrated with needs of quality, environmental and occupational safety management.
Data-driven Deep Learning for Proactive Terminal Process Management. Andreas Metzger, University of Duisburg-Essen
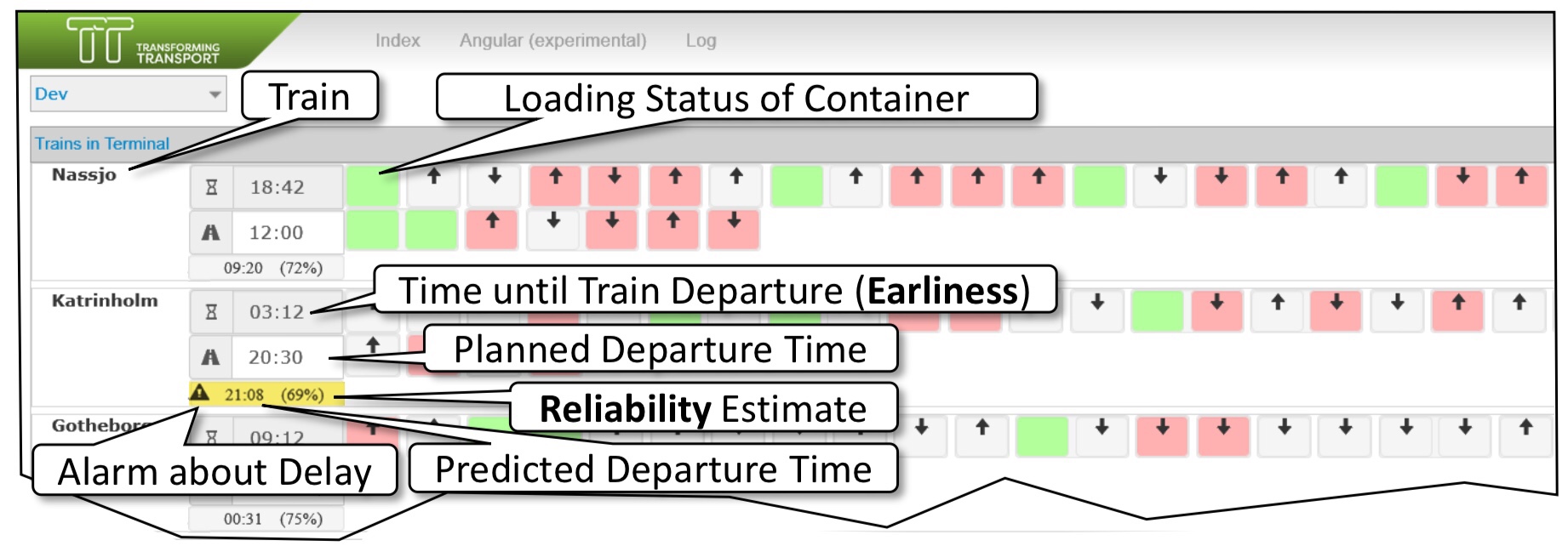
The final paper in this industry forum session was on the digitalization of the Duisberg intermodal container shipping port, a large inland port dealing with about 10,000 containers arriving and departing by rail and truck each month. Data streams from terminal equipment captured information about the movement of containers, cranes and trains; their goal was to predict based on current state whether a given train would be loaded and could depart on time, and proactively dispatch resources to speed up loading when necessary. This sounds like a straightforward problem, but the data collected can lead to erroneous results: waiting for more data to be collected can lead to more accurate predictions, but earlier intervention can resolve the problem faster.
They applied multiple parallel deep learning models (recurrent neural networks) to improve the predictions, dynamically trading off between accuracy and earliness of detection. They were able to increase the number of trains leaving on time by 4.7%, which is a great result when you consider the cost of a delayed train.
They used RNNs as their deep learning models because they can handle arbitrary length process instances without sequence or trace encoding, and can perform predictions at any checkpoint with a single model; there’s a long training time and it’s compute-intensive, but that pays off in this scenario. Lessons that they learned included the fact that the deep learning ensembles worked well out of the box, but also that the quality of the data used as input is a key concern for accuracy: if you’re going to spend time working on something, work on data cleansing before you work on the deep learning algorithms.
The Zaha Hadid-designed Library and Learning Center at UW Wien, our home for the main conference
The last segment following this is a closing panel, so this is the last of my coverage from BPM 2019. I haven’t attended this conference in many years, and I’m glad to be back. Looking forward to next year in Seville!
It’s been great to catch up with a lot of people who I haven’t seen since the last time that I attended, plus a few who I see more often. UW Wien has been a welcoming host as well as having a campus full of extraordinary modern architecture, with a well-organized conference and great evening social events.
We’re into the second day of the main BPM 2019 academic conference, and I attended the research session on management, made up of three papers, each presented by one of the authors with time for questions and discussion. Note that I’ve only listed the presenting author in each case, but you can find all of the contributors on the detailed program and read the full papers in the proceedings.
Regulatory Instability, BPM Technology, and BPM Skill Configuration. Michael zur Muehlen, Stevens Institute of Technology
Organizations have a choice on how they configure their BPM functionality and skills — this is something that I am asked about all the time in my consulting practice — and this research looked at BPM-related roles and responsibilities within three companies across different industries to see how regulatory environments can impact this. The work was based on LinkedIn data for Walmart (retail), Pfizer (pharmaceutical) and Goldman Sachs (financial), with analysis on how the regulatory environments impact the ostensive and performative aspects of processes: in other words, whether compliance issues may be due to an ostensive misfit (design of processes) or a performative misfit (exceptions and workarounds to designed processes). Some industries have a huge number of regulation/rule changes each year: more than 2,000 per year for both financial and pharma, while trade regulations (impacting retail) have few rule changes and therefore may have more stable processes. They also looked at job ads on Monster.com for a broader selection of pharma, retail and financial services companies to generate a skills taxonomy for framing the analysis.
Graph of BPM roles and skills at Walmart (From research paper)
They did some interesting text analysis on the job ads and the resumes, then mapped the roles and skills for the three companies. They found that some organizations have a bilateral configuration, where manager and analyst roles are involved in both operations and change, and a trilateral configuration, where the change functions performed by managers and project managers but not analysts. The diagram above shows the graph for Walmart; check the proceedings for the other two companies’ graphs and the full details of the analysis. They’re expanding their research to include other organizations to see what other factors (besides regulatory environment) that may be impacting how roles and responsibilities are distributed, as well as studies of how organizations change over a 20-year time period.
Understanding the Alignment of Employee Appraisals and Rewards with Business Processes. Aygun Shafagatova, Ghent University
This research is looking at the crossover between HR research on employee rewards and BPM research on people/culture aspects and BP maturity. They analyzed case studies and performed interviews in a number of companies, and performed a multi-dimensional analysis considering processes, employee roles/levels, BP maturity, reward type, and performance appraisal. They identified patterns of alignment for processes, employee roles and BP maturity, then mapped this to the performance appraisal dimension and the type of rewards (financial or non-financial) that are used for process-related performance and competence.
They identified a number of critical success factors, including rewarding the right performance and behaviors, and recommendations on evaluation and reward techniques based on BPM maturity of an organization.
Recommendations for aligning appraisals and rewards to lower and higher levels of BPM maturity (From the research paper)
I find this a very interesting topic, and have written papers and presentations on how employee incentives need to change in collaborative process environments. I also see a lot of issues related to this in my consulting practice, where employee appraisals and rewards are not aligned with newly-deployed business processes in the face of more automation and greater need for collaboration in process knowledge work.
What the Hack? – Towards a Taxonomy of Hackathons. Christoph Kollwitz, Chemnitz University of Technology
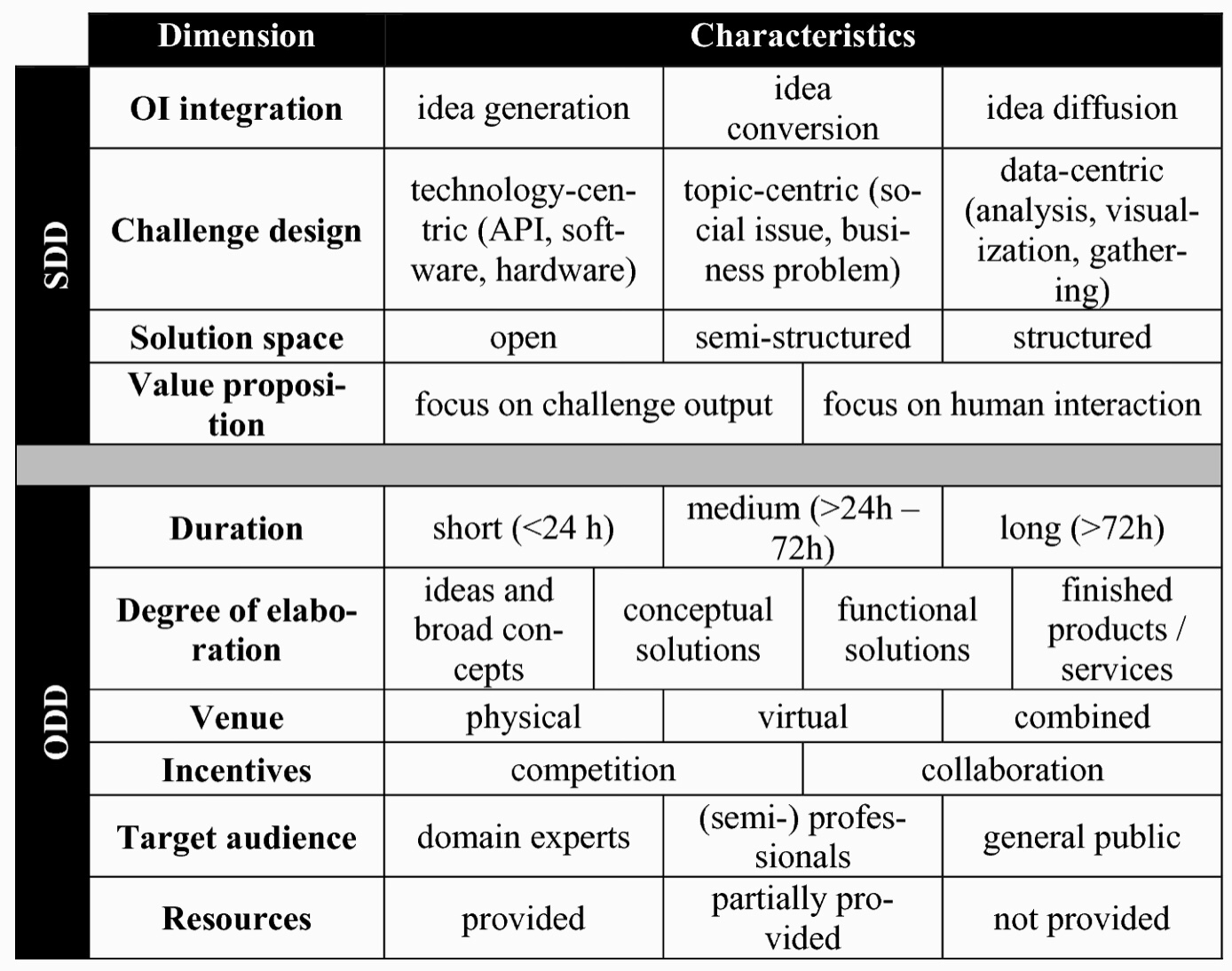
This research looked at the question of how hackathons can be used to drive/support innovation processes within organizations. The nature of hackathons combines different open innovation tools, including contests, short-period intensive workshops, communities and teamwork, and participation by both the supply and demand side of the solution space. They looked at hackathons from an organizational perspective, that is, how organizations design and execute hackathons, not from the perspective of the participants.
Based on literature reviews, they developed a taxonomy of hackathons based on strategic design decisions (SDD in the diagram) and operational design decisions (ODD). They want to conduct future research with actual case studies and interviews, and study the relationships between the individual dimensions.
Taxonomy of hackathons (From research paper)
I recently attended a session at a vendor conference where we heard about an internal hackathon at financial services firm Capital One, focused on their use of the vendor’s BPM tool. The presenter didn’t (or couldn’t) share the details of the solutions created, but focused on the organizational aspects — very similar to the topic under study in Kollwitz’ research, and possibly a good target of a case study for their future research.
The first research session that I attended at the academic BPM 2019 conference included three papers, each presented by one of the authors with time for questions and discussion. Note that I’ve only listed the presenting author in each case, but you can find all of the contributors on the detailed program and read the full papers in the proceedings.
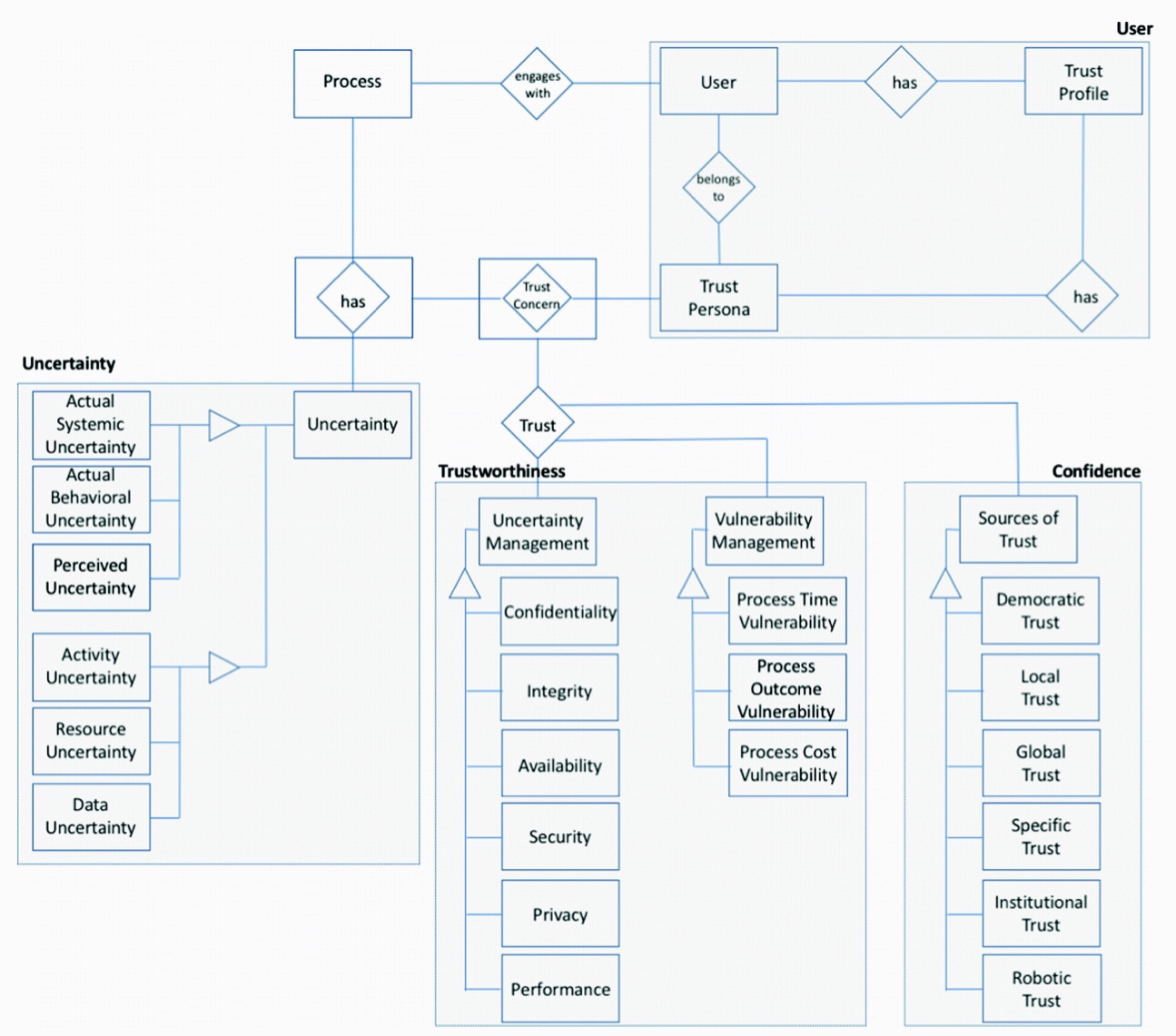
Trust-Aware Process Design. Michael Rosemann, QUT
The research context for trust concepts in process come from a variety of disciplines, with trust being defined as confidence in a relationship where some uncertainty exists. He presented a four-stage model for trust-aware process design:
Identify moments of trust, including the points where it materializes, the requirements/concerns, and the stakeholders
Reduce uncertainty, including operational, behavioral and perceived uncertainty
Reduce vulnerability, which is the cost to the process consumer in case the process does not perform as expected
Build confidence through additional information and sources such as trust in an expert
He discussed different types of trust that can be used to increase confidence at points in a process, and summarized with a meta model that shows the relationship between uncertainty, trustworthiness and confidence. He finished with some of their potential future research, such as a taxonomy for trust.
Meta model for trust-aware process design (From the research paper)
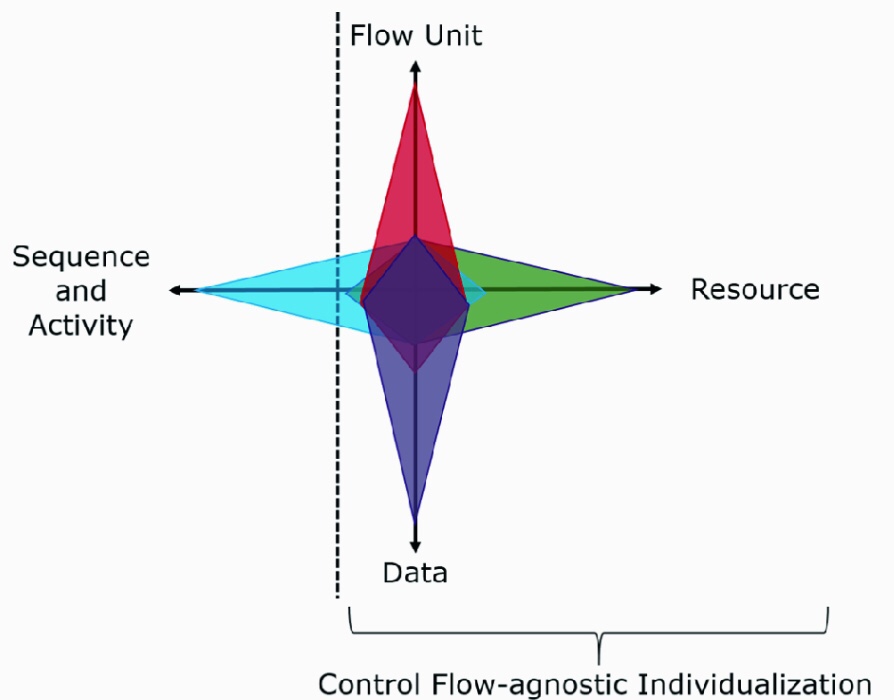
Design Patterns for Business Process Individualization. Bastian Wurm, WU Wien
There is an increased demand for individualized products and services, but this creates complexity and the need for process variants within a company: a balance between individualization to maximize revenue and standardization to minimize cost. There are different stages of individualization, from mass production (one size fits all) to mass customization (e.g., configure to order) to mass personalization (one of a kind production).
They started with a standard business process meta model, and noted that a lot of process improvement was based on reducing variants, and therefore pushing towards the mass production end of the spectrum. They generated design patterns for business process individualization:
Sequence and activity individualization, where mass personalization has activities and processes unique to each customer.
Flow unit individualization, where the sequence (process) may be standardized, but what is delivered to the customer at a specific point is unique.
Resource individualization, where the process is standardized but the resource assigned to complete a task is the most suitable match to the customer’s needs.
Data individualization, where data requested from/presented to the customer and the decisions that may be based on it is unique to the customer and context.
Their future research will include collecting primary data to test their models and hypotheses, and they’re interested in experiences or ideas from others on how this will impact BPM.
Design patterns for business process individualization (From the research paper)
Business Process Improvement Activities: Differences in Organizational Size, Culture and Resources. Iris Beerepoot, Utrecht University
This research was based on studying the daily work of healthcare professionals in five hospitals, including human activities and how they worked with (or around) the healthcare information systems. Any time that the user had to do a workaround on the system, this was considered as a deviation and examined to see if there was a poorly-designed process or system, if the individual was overstepping their authority, if there was an organizational context that required a deviation, or if there was a unique situation that required a one-time solution.
They considered the context — size, culture (flat or hierarchical organizational structure) and resources — within the five different hospitals; then they looked at snapshots of the workarounds as they occurred within specific organizations and how this impacted business process improvement activities. For example, the more hierarchical the organization, the greater importance to having management commitment and vision; in less hierarchical organizations it was more important to adhere to current culture. Larger and smaller organizations had demonstrably different ways of addressing process improvement.
Together with the studies and focus groups, they identified a fourth contextual factor (in addition to size, culture and resources): the maturity of an organization. I assume there is some degree of correlation between some of these factors, for example, a larger organization may be more likely to have a more hierarchical culture and greater resources.
Good audience discussion at the end about the nature of workarounds — intentional/unintentional versus positive/negative — and the potential inclusion of endogenous factors in addition to the exogenous ones used in this study. As with all of the research papers, there are plenty of future research directions possible.
I attended the tutorial on Exploring Explorative Business Process Management with Max Röglinger, Thomas Grisold, Steven Gross and Katharina Stelzl, representing Universität Liechtenstein, Universität Bayreuth and Wirtschafts Universität Wien. This was a good follow-on from Kalle Lyytinen’s keynote with the themes of emerging processes routines, and looked at the contrast between maximizing operational efficiency on pre-defined processes, and finding completely new ways of doing things: doing things right versus doing the right thing.
They frame these as exploitative BPM — the traditional approach of maximizing operational efficiency — and explorative BPM as a driver for innovation. Anecdotal evidence aside, there is research that shows that (pre-defined) BPM activities impede radical innovation because the lack of variance in processes means that we rarely have “unusual experiences” that might inspire radical new ways of doing things. In fact, most of the BPM research and literature is on incrementally improving business processes (usually via analytics), not process innovation or even process redesign.
The division between exploitative (improvement) and explorative (innovation) activities comes from organizational science, with “organizational ambidexterity” a measure of how well an organization can balance exploitation and exploration as they manage change. This can be seen to align with people and teams with delivery skills (analyzing, planning, implementation, self-discipline) versus those with discovery skills (associating, questioning, observing, networking, experimenting), and the need for both sides to work together.
In their research, they have defined three dimensions of process design — trigger, action and value proposition — with combinations of these for problem-driven versus opportunity-driven process improvement/innovation. Explorative BPM results in reengineered (not just incrementally improved) processes or completely new processes to offer the same, enhanced or new value propositions. In general, their definition of opportunities is tied to top-level business goals, while problems are essentially operational pain points. There was a discussion around the nature of problems and opportunities, and how the application of BPM (and BPM research) is expanding to more than just classical process management but also supporting business model innovation.
Three dimensions of BPM (From the tutorial research paper)
Having set the stage for what explorative BPM is and why it is important, we had a group exercise to explore explorative BPM, and generate ideas for how to go about process innovation. To finish the tutorial, they presented the results of their tutorial research paper with a potential method for explorative BPM: the triple diamond model.
Triple Diamond Model for explorative BPM (From the tutorial research paper)
Future research directions for explorative BPM may include ideas from other domains/disciplines; organizational capabilities required for explorative BPM; and the tools, methods and techniques required for its implementation.