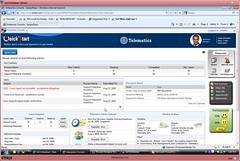
 I recently had a chance for an in-depth update on Lombardi’s Blueprint – a cloud-based process modeling tool – to see a number of the new features in the latest version. I haven’t had a chance to look at it in detail for over a year, and am impressed by the social networking tools that are built in now: huge advances in the short two years since Lombardi first launched Blueprint. The social networking tools make this more than just a Visio replacement: it’s a networking hub for people to collaborate on process discovery and design, complete with a home page that shows a feed of everything that has changed on processes that you are involved in. There’s also a place for you to bookmark your favorite processes so that you can easily jump to them or see who has modified them recently.
I recently had a chance for an in-depth update on Lombardi’s Blueprint – a cloud-based process modeling tool – to see a number of the new features in the latest version. I haven’t had a chance to look at it in detail for over a year, and am impressed by the social networking tools that are built in now: huge advances in the short two years since Lombardi first launched Blueprint. The social networking tools make this more than just a Visio replacement: it’s a networking hub for people to collaborate on process discovery and design, complete with a home page that shows a feed of everything that has changed on processes that you are involved in. There’s also a place for you to bookmark your favorite processes so that you can easily jump to them or see who has modified them recently.
At a high level, creating processes hasn’t changed all that much: you can create a process using the outline view by just typing in a list of the main process activities or milestones; this creates the discovery map simultaneously on the screen, which then allows you to drag steps under the main milestone blocks to hierarchically indicate all the steps that make up that milestone. There have been a number of enhancements in specifying the details for each step however: you can assign roles or specific people as the participant, business owner or expert for that step; document the business problems that occur at that step to allow for some process analysis at later stages; create documentation for that step; and attach any documents or files to make available as reference materials for this step. Once the details are specified, the discovery map view (with the outline on the left and the block view on the right) shows the participants aligned below each milestone, and clicking on a participant shows not only where it is used in this process, but where it is used in all other processes in the repository.
 At this point, we haven’t yet seen a bit of BPMN or anything vaguely resembling a flowchart: just a list of the major activities and the steps to be done in each one, along with some details about each step. It would be pretty straightforward for most business users to learn how to use this notation to do an initial sketch of a process during discovery, even if they don’t move on to the BPMN view.
At this point, we haven’t yet seen a bit of BPMN or anything vaguely resembling a flowchart: just a list of the major activities and the steps to be done in each one, along with some details about each step. It would be pretty straightforward for most business users to learn how to use this notation to do an initial sketch of a process during discovery, even if they don’t move on to the BPMN view.
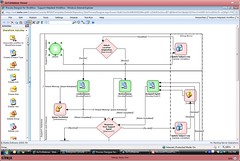
Switching to the process diagram view, we see the BPMN process map corresponding to the outline view created in the discovery map view, and you can switch back and forth between them at any time. The milestones are shown as time bands, and if participants were identified for any of the steps, swimlanes are created corresponding to the participants. Each of the steps is placed in a simple sequential flow to start; you can then create gateways and any other elements directly in the process map in this view. The placement of each element is enforced by Blueprint, as well as maintaining a valid BPMN process map.
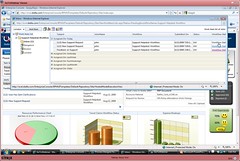
There’s also a documentation view of the process, showing all of the documentation entered in the details for any step.
Not everyone will have access to Blueprint, however, so you can also generate a PowerPoint file with all of the process details, including analysis of problem areas identified in the step details; a PDF of the process map; a Word document containing the step documentation; an Excel spreadsheet containing the process data; and a BPDM or XPDL output of the process definition. It will also soon support BPMN 2.0 exports. Process maps can also be imported from Visio; Blueprint analyzes the Visio file to identify the process maps within it, then allows the user to select the mapping to use from the Visio shapes into Blueprint element types.
 There are other shared process modeling environments that do many of the same things, but the place where Blueprint really shines is in collaboration. It’s a shared whiteboard concept, so that users in different locations can work together and see the changes that each other makes interactively without waiting for one person to check the final result into a repository: an idea that is going to take hold more with the advent of technologies such as Google Wave that raise the bar for expectations of interactive content sharing. This level of interactivity will undoubtedly reduce the need for face-to-face sessions: if multiple people can view and interact simultaneously on a process design, there probably needs to be less time spent in a room together doing this on a whiteboard.There’s a (typed) chat functionality built right into the product, although most customers apparently still use conference calls while they are working together rather than the chat feature: hard to drag and drop things around on the process map while typing in chat at the same time, I suppose. Blueprint maintains a proper history of the changes to processes, and allows viewing of or reverting to previous versions.
There are other shared process modeling environments that do many of the same things, but the place where Blueprint really shines is in collaboration. It’s a shared whiteboard concept, so that users in different locations can work together and see the changes that each other makes interactively without waiting for one person to check the final result into a repository: an idea that is going to take hold more with the advent of technologies such as Google Wave that raise the bar for expectations of interactive content sharing. This level of interactivity will undoubtedly reduce the need for face-to-face sessions: if multiple people can view and interact simultaneously on a process design, there probably needs to be less time spent in a room together doing this on a whiteboard.There’s a (typed) chat functionality built right into the product, although most customers apparently still use conference calls while they are working together rather than the chat feature: hard to drag and drop things around on the process map while typing in chat at the same time, I suppose. Blueprint maintains a proper history of the changes to processes, and allows viewing of or reverting to previous versions.
Newly added is the ability to share processes in reviewer mode to a larger audience for review and feedback: users with review permissions (participants as opposed to authors) can view the entire process definition but can’t make modifications; they can, however, add comments on steps which are then visible to the other participants and authors. Like authors, reviewers can switch between discovery map, process diagram and documentation views, although their views are read-only, and add comments to steps in either of the first two views. Since Blueprint is hosted in the cloud, both authors and reviewers can be external to your company; however, user logins aren’t shared between Blueprint accounts but have to be created by each company in their account. It would be great if Blueprint provided authentication outside the context of each company’s account so that, for example, if I were participating in two project with different clients who were both Blueprint customer and I was also a Blueprint customer, they wouldn’t both have to create a login for me, but could reuse my existing login. Something like this is being done by Freshbooks, an online time tracking and invoicing applications, so that Freshbooks customers can easily more interact. Blueprint is providing the ability to limit access in order to meet some security standards: access to a company’s account can be limited to their own network (by IP address), and external participants can be restricted to be from specific domains.
One issue that I have with Blueprint, and have been vocal about in the past, is the lack of a non-US hosting option. Many organizations, including all of my Canadian banking customers, will not host anything on US-based servers due to the differences in privacy laws; even though, arguably, Blueprint doesn’t contain any customer information since it’s just the process models, not the executable processes, most of them are pretty conservative. I know that many European organizations have the same issues, and I think that Lombardi needs to address this issue if they want to break into non-US markets in a significant way. Understandably, Lombardi has resisted allowing Blueprint to be installed inside corporate firewalls since they lose control of the upgrade cycle, but many companies will accept hosting within their own country (or group of countries, in the case of the EU) even if it’s not on their own gear.
Using a cloud-based solution for process modeling makes a lot of sense in many situations: nothing to install on your own systems and low-cost subscription pricing, plus the ability to collaborate with people outside your organization. However, as easy as it is to export from Blueprint into a BPMS, there’s still the issue of round-tripping if you’re trying to model mostly automated processes.