I’ve written another post for the Trisotech blog on end-to-end processes, and how Conway’s Law can prevent good horizontal integration across your organization’s processes. Conway’s Law is an adage that states that organizations design systems that mirror their own communication structure: basically, if your interdepartmental communications is not that great, the underlying systems are unlikely to do a good job of it either.
I go into some detail of the problems that occur when an organization is functionality siloed with poor communication between areas, and how you can start to find your way out of it.
You can find all of the posts that I’m creating for them here.
I’ll be writing a few guest posts over on the Trisotech blog, starting with this one on goal alignment through the hierarchy of your orgnization to make sure that you’re not only doing the right thing, but doing the thing right. As I mention over there, I have this conversation with almost every enterprise client that I talk to, and thought it would be good to put down some thoughts around a goal alignment structure like this:
This is (techinically) sponsored content, although I don’t discuss Trisotech products at all, so I’m not reprinting it here but encourage you to head over there and give it a read.
I thought that I was done with my CamundaCon coverage, but noticed that Jakob Freund is blogging more details about what he covered in his keynote. I spent most of his keynote behind the curtain waiting for my turn to speak, but was able to see it again when they posted the video of his presentation.
He’s doing a five-part series on the themes that he covered, based in part on their experiences with their clients over the past years, with the first two available here:
Part 1: Intro to the four key elements of becoming a digital enterprise
Part 2: The first key element, customer-focused innovation
If he keeps to his posting schedule, the next one should be up tomorrow.
On November 12, I’ll be expanding on some of those themes in a webinar sponsored by Camunda:
Why a monolithic architecture, whether a legacy application or an all-in-one business automation platform, lacks the agility and scalability required for businesses to survive and thrive
How a best-of-breed business automation platform can be assembled from a set of components in a microservices architecture
How to migrate from your legacy systems to a best-of-breed business automation platform
In particular, the new bit on migrating legacy systems is drawn from my best practices developed over years of consulting as a systems architect/designer.
You can sign up for the webinar here; if you can’t make it on that date, sign up anyway and you’ll get a link to the recording.
Friedbert Samland from Deutsche Telekom IT and Willm Tüting from their technology partner conology presented on Telekom IT (the internal IT provider for Deutsche Telekom) migrating from monolithic systems to a microservices architecture while also moving from waterfall to Agile development methodologies. In 2017, they had a number of significant problems with their monolithic system for wholesale orders: time to market for new features was 12+ months, lots of missing functionality that required manual steps, vendor lock-in, large (therefore risky and time-consuming) releases, and more.
Willm Tüting and Friedbert Samland presenting on the problems with Telekom IT’s monolithic wholesale ordering system
They tried a variety of approaches to alleviate these problems, such as a partial Agile environment, but needed something more radical to make a difference. They identified four major drivers: microservices, cloud, SAFe (Scaled Agile Framework) and devops. I’m sure everyone in the audience was familiar with those concepts, but they went through how this actually works in a large organization like this, where it’s not always as easy as the providers say it will be. They learned a lot of lessons the hard way, such as the long learning curve of moving to cloud.
They were migrating a system built on the Oracle BPEL engine, starting by partitioning the monolith in terms of data and functionality (logic and processes) in order to identify three categories of microservices: business process microservices, data microservices, and domain-specific microservices. They balanced orchestration and choreography with a “choreographed orchestration” of the microservices, where the (Camunda) process orchestrations were embedded within the microservices for handling processes and inter-service communication. By having separate Camunda instances with separate databases for each microservice (which provides a high degree of scalability), they had to enhance the monitoring to get an aggregated view of all of the process flows.
This is a great example of a real-world large-scale implementation where a proprietary and monolithic iBPMS just would not work for the architecture that Telekom IT needed: Camunda BPM is embedded in the services, it doesn’t pre-suppose fixed orchestration at the top level of an application.
Although we’re just halfway through the last day, this was my last session at CamundaCon, I’m headed south for a short weekend break then DecisionCamp in Bolzano next week. Thanks to the entire Camunda team for putting on a great event, and inviting me to give a keynote yesterday.
Camunda co-founder Bernd Rücker presented on some of the implementation issues with microservices, in particular following on from Susanne Kaiser’s keynote with the theme of having small delivery teams spend more of their time developing business capabilities and less on the “undifferentiated heavy lifting” infrastructure bits required to support those. This significantly reduces the cognitive load for the team, allowing them to build the best possible business capabilities without worrying about arcane configuration details. Interestingly, this is not that different from the argument to move from a business process embedded within a business system logic to an externalized process in a BPMS — something that Bernd has a long history with.
He went through an example of the services behind a train ticket booking, which requires payment, seat reservation and ticket generation services; there are issues of latency and uptime as well as the user experience of how the results of those services are presented to the customer. He referenced the Reactive Manifesto as a guideline for software design patterns that are “more robust, more resilient, more flexible and better positioned to meet modern demands”.
Event-driven choreography is a common pattern these days, but has the problem of not being able to visualize the overall process flow between services. This can be alleviated somewhat by using event monitoring overlaid on a process model — effectively process discovery if the flow is not standardized or when it changes — or even more so by orchestrating standard parts of the flow to combine event-driven and orchestration patterns. Orchestration has the advantage of relocating the coupling between services in an event-driven flow to the orchestration layer: although event choreography is seen as loosely-coupled, there’s a lot of event listening that has to be built into the services, which couples them more closely. It’s not that one is good and the other bad: there’s a place for both choreography and choreography patterns in software development.
He finished with a discussion of monolithic legacy software and how to deal with it: from the initial step of just adding APIs to access functionality, you gradually chip away at the monolith’s capabilities, ripping them out replacing with externalized services.
Susanne Kaiser, former CTO of Just Social and now an independent technology consultant, opened the second day of CamundaCon 2019 with a presentation on moving to a microservices architecture, particularly for a small team. Similar to the message in my presentation yesterday, she advises building the processes that are your competitive differentiator, then outsourcing the rest to external vendors.
She walked through some of the things to consider when designing microservices, such as the ideas of bounded context, local data persistence, API discovery and management, linkage with message brokers, and more. There’s a lot of infrastructure complexities in building a single microservice, which makes it particularly challenging for small teams/companies — that’s part of what drives her recommendation to outsource anything that’s not a competitive differentiator.
Susanne Kaiser and the complexities of building a single microservice
She showed the use of Wardley maps for the evolution of a value chain, showing how components are mapped relative to their visibility to users and their level of maturity. Components of a solution/system are first identified by their visibility, usually in a top-down manner based on the functional requirements. They are then plotted along the evolution axis, to identify which will be custom-built versus those that are third-party products or outsourced commodities/utilities. This includes identifying all of the infrastructure to support those components; initially, this may include a lot of the infrastructure components as requiring custom build, but use of third-party products (including open source) can shift many of these components along the evolution axis.
Sample Wardley Map development for a solution (mid-evolution)
She then showed how Camunda BPM would fit into this map of the solution, and how it can abstract away some of the activities and components that were previously explicit. In short, Camunda BPM is a higher-level piece of infrastructure that can handle service orchestration including complexities of retries and more. I haven’t worked with Wardley Maps previously, and there are definitely some good concepts in here for helping to identify buy versus build components in a technical architecture.
Derek Vandivere of ING Netherlands finished up the first day of CamundaCon 2019 here in Berlin taking about how they moved from a regional to global platform migration — strange, because he’s actually talking about their Pega implementation although they’re also implementing Camunda — and how to work around the monoliths. I know that Derek’s wife is an art restorer, and this has obvious rubbed off on him since all of his slides were photos of Dutch Masters paintings that were (however peripherally) related to his subject matter.
Different ING regional operations selected different BPM engines: the Netherlands went with Pega, while Germany went with Camunda, with other areas building their own thing or using legacy TIBCO. They’re attempting to build some standards around how people talk about BPM and case management internally, as well as how applications are developed. As a global bank, they need to have some data, rules and processes that span countries, making it necessary to consider how to bring all of these disparate systems together.
Derek Vandivere discusses the challenges of having multiple vendors’ BPMS
He went through a number of the best practices and lessons learned that they discovered along the way as they rolled out a regional solution globally. Although his experience with the Dutch implementation was based on Pega, there are many transferrable lessons here, since a lot of it is about higher-level architecture, bottlenecks in processes and decision-making (often human bottlenecks, although some technical as well), and how to interact with the business areas.
He discussed with the current pressures on their monolithic iBPMS (Pega) platform that echoed some of what I talked about this morning: proprietary developer training, container-based microservices architecture, and multiple distributed deployment models (support for both cloud and regionally-mandated on-premise). Replacing or upgrading any sufficient complex IT is going to be a challenging task, but doing that with a monolithic iBPMS is considerably more challenging than a more distributed microservices architecture.
We’re about to spill out onto the Spree-side patio here at Radialsystem V for a BBQ and well-deserved refreshments, so that’s it for my coverage of this first day at CamundaCon 2019. I’ll be back for a couple of sessions tomorrow morning before heading south to Bolzano for next week’s DecisionCamp.
Sowmya Raghunathan and Corinna Cohn presented on a claims intake implementation that uses BPMN and DMN in an interesting way: driving the intake forms used by a claims administrator when gathering first notice of loss (FNOL) information from a claimant. The idea is that the claims admin doesn’t need to have any information about the claim type, and the claimant doesn’t get asked any irrelevant questions, because the form always presents the next best question based on previous responses: a wizard-like model, but driven by BPMN and DMN.
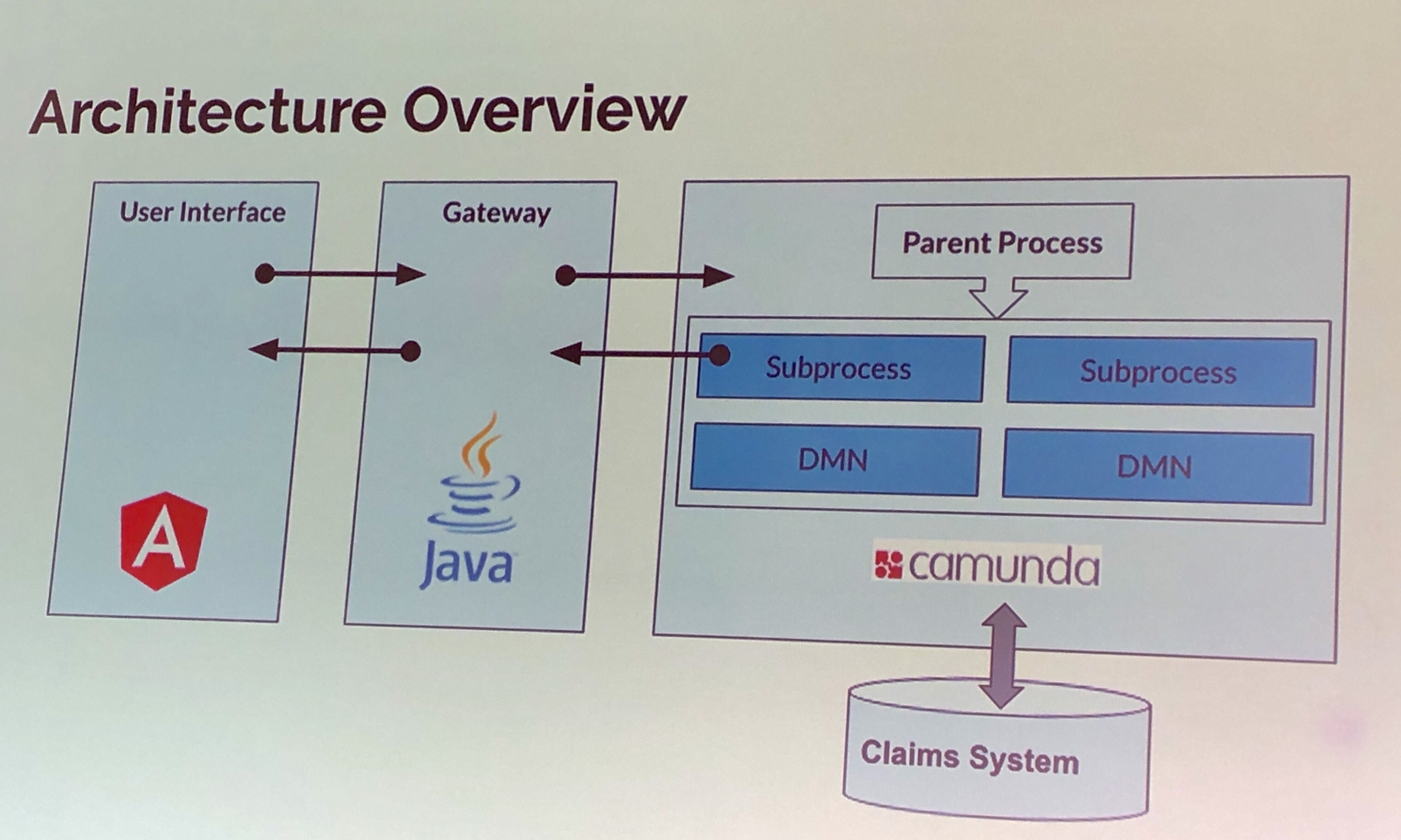
As the application and technical architects at Indiana Farm Bureau Insurance, they were able to give us a good view of how they use the tools for this: BPMN for orchestrating the DMN and UI communication as well as storing the responses, DMN for defining the questions and question/response mapping, and a UI component for implementing the survey forms. They consider this a headless application, but of course, it does surface via the form UI; from a Camunda process standpoint, however, it is decoupled piece of the architecture that interfaces with the claims system.
Technical architecture of the survey DMN/BPMN system
We saw a demo of one of the claim forms at work, where the previous questions and responses can be seen, and changes to the previous responses may cause changes to subsequent questions based on the DMN decision tables behind the scenes. They use a couple of DMN tables just as configuration tables for the UI for the questions and options (e.g., radio buttons versus free-form responses), then a Next Question decision table to determine the next question based on the previous response: this table is based on a directed acyclic graph that links questions (nodes) via answers (links), which allows for easy re-navigation of the graph if an earlier response is changed.
DMN decision table for FNOL questions related to auto claim
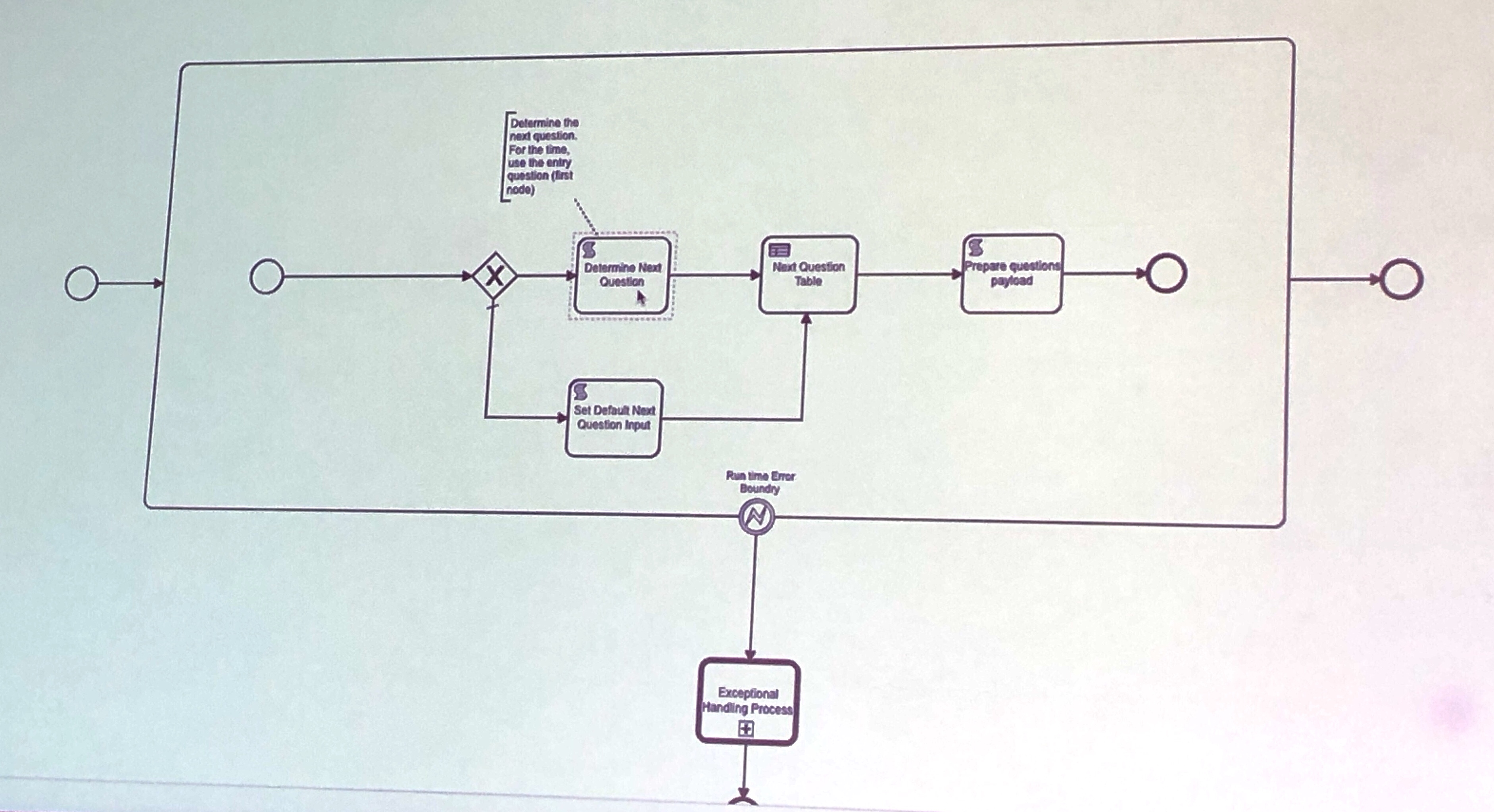
BPMN is used to navigate and determine the next question in a dynamic question subprocess, and if the survey can be exited; once sufficient information has been collected, the FNOL is initiated in the claims systems.
Dynamic Questions BPMN subprocess
The use of DMN means that the questions can be changed very easily since they’re not embedded in the code; this means that they can be created and modified by business analysts rather than requiring developers to code these into the UI directly.
FNOL BPMN process
The entire framework is reusable, and could be quickly reconfigured to be used for any type of survey. That’s great, because a few years ago, I saw a very similar use case for this in a clinical situation for a stroke assessment questionnaire: in a hospital setting, when someone arrives at an emergency department and is suspected of having had a stroke, there are standard questions to ask in order to evaluate the patient’s condition. At the time, I thought that this would be a perfect use case for DMN and BPMN, although that was beyond the scope of the project at that time.
Niko Vogel of AXA Germany and Matthias Schulte of their consulting partner viadee presented on AXA’s journey from a process engine that they built in-house to a Camunda cloud-based process engine. This was driven by their move to a new policy management system, with the goal to automate as much as possible of their end-to-end travel and health insurance process, and support the knowledge workers for the human tasks.
They’ve seen a huge change in how business and IT work together: collaborating over process optimization and troubleshooting, for example. They have a central team for more of the infrastructure issues such as reporting and security, as well as acting as a center of excellence for BPMN and DMN.
Niko Vogel of AXA discussing how they use Camunda
They have made some extensions to Camunda’s Cockpit dashboard to tie in more business information, allowing business users to access it directly for looking up specific policy-related processes and see what’s happening with them. They’ve also done a “DMN Manager” extension to control the modification and deployment of decision tables, although changes to decision tables can still be done by the business without involvement from IT. Another significant extension is to collect runtime statistics from Camunda and other line-of-business systems to do some analysis on the aggregate; based on something that we saw in Daniel’s keynote this morning, this capability may soon be something offered directly by Camunda.
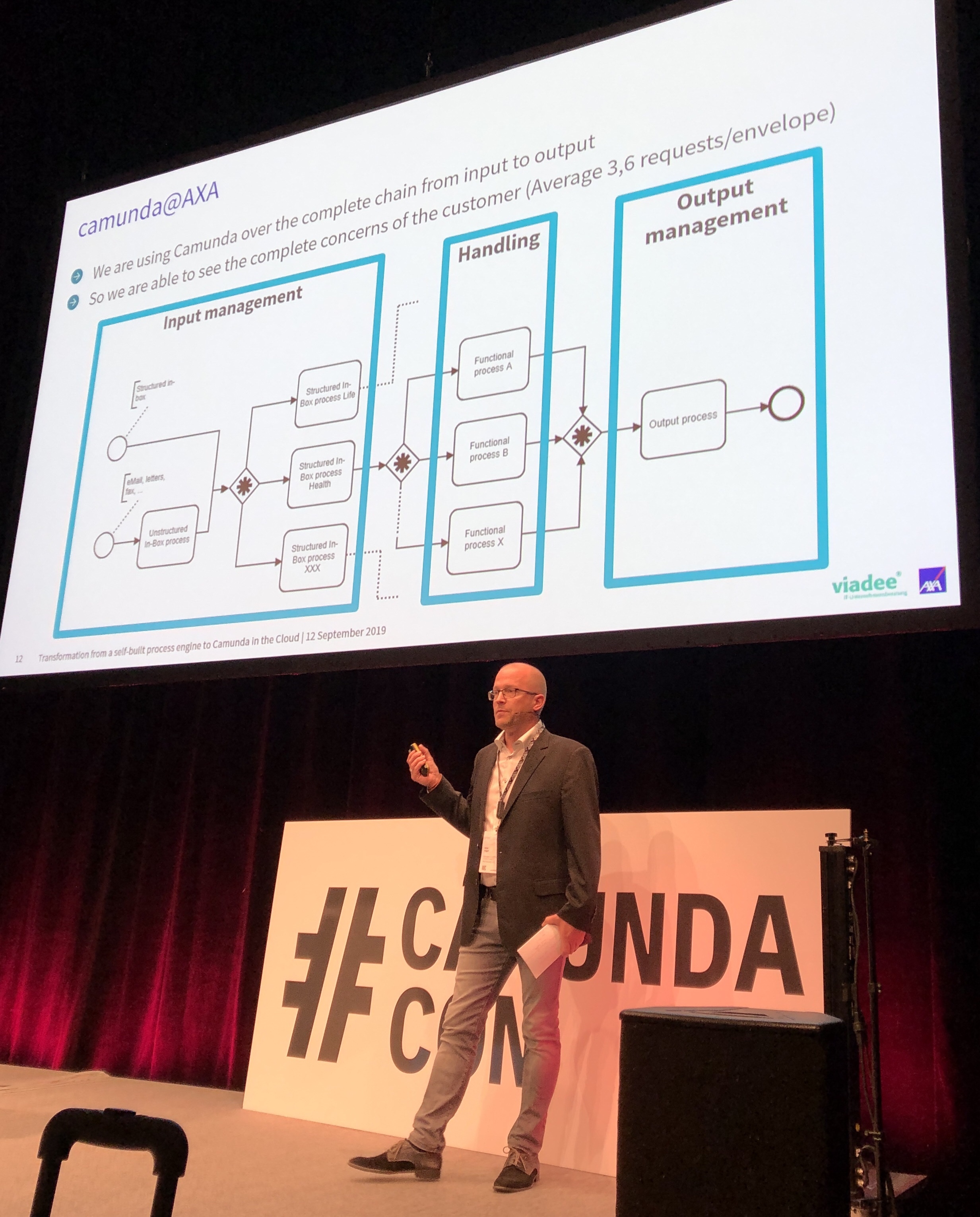
Their architecture started as a “shared monolith” in 2017, that is, a central deployment of a single Camunda server instance used by all process applications — note that this is the primary deployment model for many BPMS. They felt this was a good first step, but moved to a decentralized Spring Boot architecture to create decentralized standalone applications, although common tools remained in a shared instance.
Now, they’re moving to the cloud, which allows reuse of their existing service access architecture (integrating with policy administration system, for example) via tunneling in a very similar way as they used with the on-premise Spring Boot implementation. The current point of discussion is about how many databases to use: they are likely to move from their current centralized database to a less centralized model. This will give them much better elastic scalability and performance — a common database is a classic chokepoint when scaling — although this will require some definite rework to determine how to split up the databases and how to handle cross-application reporting in a transparent fashion.
Good questions and discussion with the audience at the end, including managing their large process model as it moves through business-IT collaboration to deployment.