Opening day at IBM Impact 2012 (there were some sessions yesterday, but today is the real start), and a good keynote focused on innovation. The wifi is appalling – if IBM can’t get this right with their messages about scalability, who can? – so not sure if I’ll have the chance to post any of this throughout the day, or if you’ll get it all when I get back to my hotel room.
This post is based on a pre-conference briefing that I had a week or two ago, a regular conference breakout session this morning, and the analyst briefing this afternoon, covering IBM’s vision for BPM, ODM (decision management) and SOA. Their customers are using technology to drive process innovation, and the IBM portfolio is working to address those needs. Cross-functional business outcomes, which in turn require cross-functional processes, are enabled by collaboration and by better technical integration across silos. And, not surprisingly, their message is moving towards the Gartner upcoming iBPMS vision: support for structured and unstructured process; flexible integration; and rules and analytics for repeatable, flexible decisions. Visibility, collaboration and governance are key, not just within departmental processes, but when linking together all processes in an organization into an enterprise process architecture.
The key capabilities that they offer to help clients achieve process innovation include:
- Process discovery and design (Blueworks Live)
- Business process management (Process Server and Process Center)
- Operational decision management (Decision Server and Decision Center)
- Advanced case management (Case Manager, which is the FileNet-based offering that not part of this portfolio, but integrated)
- Business monitoring (Business Monitor)
Underpinning these are master data management, integration, analytics and enterprise content management, surrounded by industry expertise and solutions. IBM is using the term intelligent business operations (which was front and center at Gartner BPM last week) to describe the platform of process, events and decision, plus appropriate user interfaces for visibility and governance.
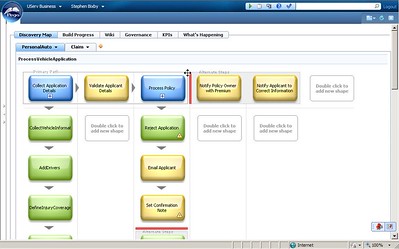
Blueworks Live is positioned not just as a front-end design tool for process automation, but as a tool for documenting processes. Many of the 300,000 processes that have been documented in Blueworks Live are never automated in IBM BPM or any other “real” BPMS, but it acts as a repository for discovering and documenting processes in a collaborative environment, and allowing process stakeholders to track changes to processes and see how it impacts their business. There is an expanded library of templates, plus an insurance framework and other templates/frameworks coming up.
One exciting new feature (okay, exciting to me) is that Blueworks Live now allows decision tasks to be defined in process models, including the creation of decision tables: this provides an integrated process/decision discovery environment. As with process, these decisions do not need to become automated in a decision management system; this may just document the business rules and decisions as they are applied in manual processes or other systems.
Looking at IBM BPM v8, which is coming up soon, Ottosson took us through the main features:
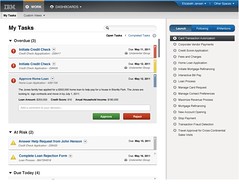 Social collaboration to allow users to work together on tasks via real-time interactions, view activity streams, and locate experts. That manifests in the redesigned task interface, or “coach”, with a sidebar that includes task details, the activity stream for the entire process, and experts that are either recommended by the system based on past performance or by others through manual curation. Experts can be requested to collaboration on a task with another user – it includes presence, so that you can tell who is online at any given time – allowing the expert to view the work that the user is doing, and offer assistance. Effectively, multiple people are being given access to same piece of work, and updates made by anyone are shown to all participants; this can be asynchronous or synchronous.
Social collaboration to allow users to work together on tasks via real-time interactions, view activity streams, and locate experts. That manifests in the redesigned task interface, or “coach”, with a sidebar that includes task details, the activity stream for the entire process, and experts that are either recommended by the system based on past performance or by others through manual curation. Experts can be requested to collaboration on a task with another user – it includes presence, so that you can tell who is online at any given time – allowing the expert to view the work that the user is doing, and offer assistance. Effectively, multiple people are being given access to same piece of work, and updates made by anyone are shown to all participants; this can be asynchronous or synchronous. - There is also a redesigned inbox UI, with a more up-to-date look and feel with lots of AJAX-y goodness, sorting and coloring by priority, plus the ability to respond to simple tasks inline directly in the inbox rather than opening a separate task view. It provides a single task inbox for a variety of sources, including IBM BPM, Blueworks workflows and Case Manager tasks.
- Situational awareness with process monitoring and analysis in a performance data warehouse.
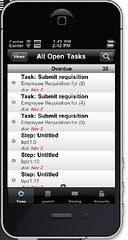 Mobile access via an iOS application that can interface with Blueworks Live and IBM BPM; if you search for “IBM BPM” in the iTunes app store (but not, unfortunately, in the Android Market), you’ll find it. It supports viewing the task list, task completion, attach documents and add comments. They are considering releases the source code to allow developers to use it as a template, since there is likely to be a demand for a customized or branded version of this. In conjunction with this, they’ve released a REST API tester similar to the sort of sandbox offered by Google, which allows developers to create REST-based applications (mobile or otherwise) without having to own the entire back-end platform. This will certainly open up the add-on BPM application market to smaller developers, where we are likely to see more innovation.
Mobile access via an iOS application that can interface with Blueworks Live and IBM BPM; if you search for “IBM BPM” in the iTunes app store (but not, unfortunately, in the Android Market), you’ll find it. It supports viewing the task list, task completion, attach documents and add comments. They are considering releases the source code to allow developers to use it as a template, since there is likely to be a demand for a customized or branded version of this. In conjunction with this, they’ve released a REST API tester similar to the sort of sandbox offered by Google, which allows developers to create REST-based applications (mobile or otherwise) without having to own the entire back-end platform. This will certainly open up the add-on BPM application market to smaller developers, where we are likely to see more innovation. - Enhancements to Process Center for federation of different Process Centers, each of which implies a different server instance. This allows departmental instances to share assets, as well as draw from an internal center of excellence plus one hosted by IBM for industry standards and best practices.
- Support for the CMIS standard to link to any standard ECM repository, as well as direct integration to FileNet ECM, to link documents directly into processes through a drag-and-drop interface in the process designer.
- There are also some improvements to the mashup tool used for forms design using a variety of integration methods, which I saw in a pre-conference briefing last week. This uses some of the resources from IBM Mashup Centre development team, but the tool was built new within IBM BPM.
- Cloud support through IBM SmartCloud which appears to be more of a managed server environment if you want full IBM BPM, but does offer BPM Express as a pre-installed cloud offering. At last year’s Impact, their story was that they were not doing BPM (that is, execution, not the Blueworks-type modeling and lightweight workflow) in the cloud since their customers weren’t interested in that; at that time, I said that they needed to rethink their strategy on this and and stop offering expensive custom hosted solutions. They’ve taken a small step by offering a pre-installed version of BPM Express, but I still think these needs to advance further.
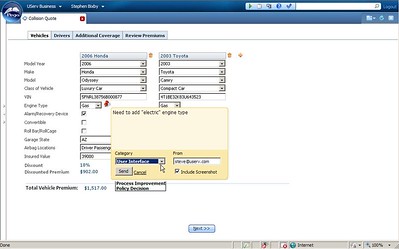
WebSphere Operational Decision Management (ODM) is a integration/bundling of WebSphere Business Event Manager and ILOG, bringing together events and rules into a single decision management platform for creating policies and deploying decision services. It has a number of new features:
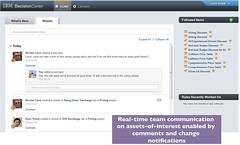 Social interface for business people to interact with rules design: decisions are assets that are managed and modified, and the event stream/conversation shows how those assets are being managed. This interface makes it possible to subscribe to changes on specific rules.
Social interface for business people to interact with rules design: decisions are assets that are managed and modified, and the event stream/conversation shows how those assets are being managed. This interface makes it possible to subscribe to changes on specific rules. - Full text searching across rules, rule flows, decision tables and folders within a project, with filtering by type, status and date.
- Improved decision table interface, making it easier to see what a specific table is doing.
- Track rule versions through a timeline (weirdly reminiscent of Facebook’s Timeline), including snapshots that provide a view of rules at a specific point in time.
- Any rule can emit an event to be consumed/managed by the event execution engine; conversely, events can invoke rulesets. This close integration of the two engines within ODM (rules and events) is a natural fit for agile and rapid automated decisions.
There’s also zOS news: IBM BPM v8 will run on zOS (not sure if that includes all server components), and the ODM support for zOS is improved, including COBOL support in rules. It would be interesting to see the cost relative to other server platforms, and the compelling reasons to deploy on zOS versus those other platforms, which I assume are mostly around integrating with other zOS applications for better runtime performance.
Since last year’s big announcement about bringing the platforms together, they appear to have been working on integration and design, putting a more consistent and seamless user interface on the portfolio as well as enhancing the capabilities. One of the other analysts (who will remain nameless unless he chooses to identify himself) pointed out that a lot of this is not all that innovative relative to market leaders – he characterized the activity stream social interface as being like Appian Tempo three years ago, and some of the functionality as just repackaged Lombardi – but I don’t think that it’s necessarily IBM’s role to be at the very forefront of technology innovation in application software. By being (fairly) fast followers, they have the effect of validating the market for the new features, such as mobile and social, and introducing their more conservative customer base to what might seem like pretty scary concepts.