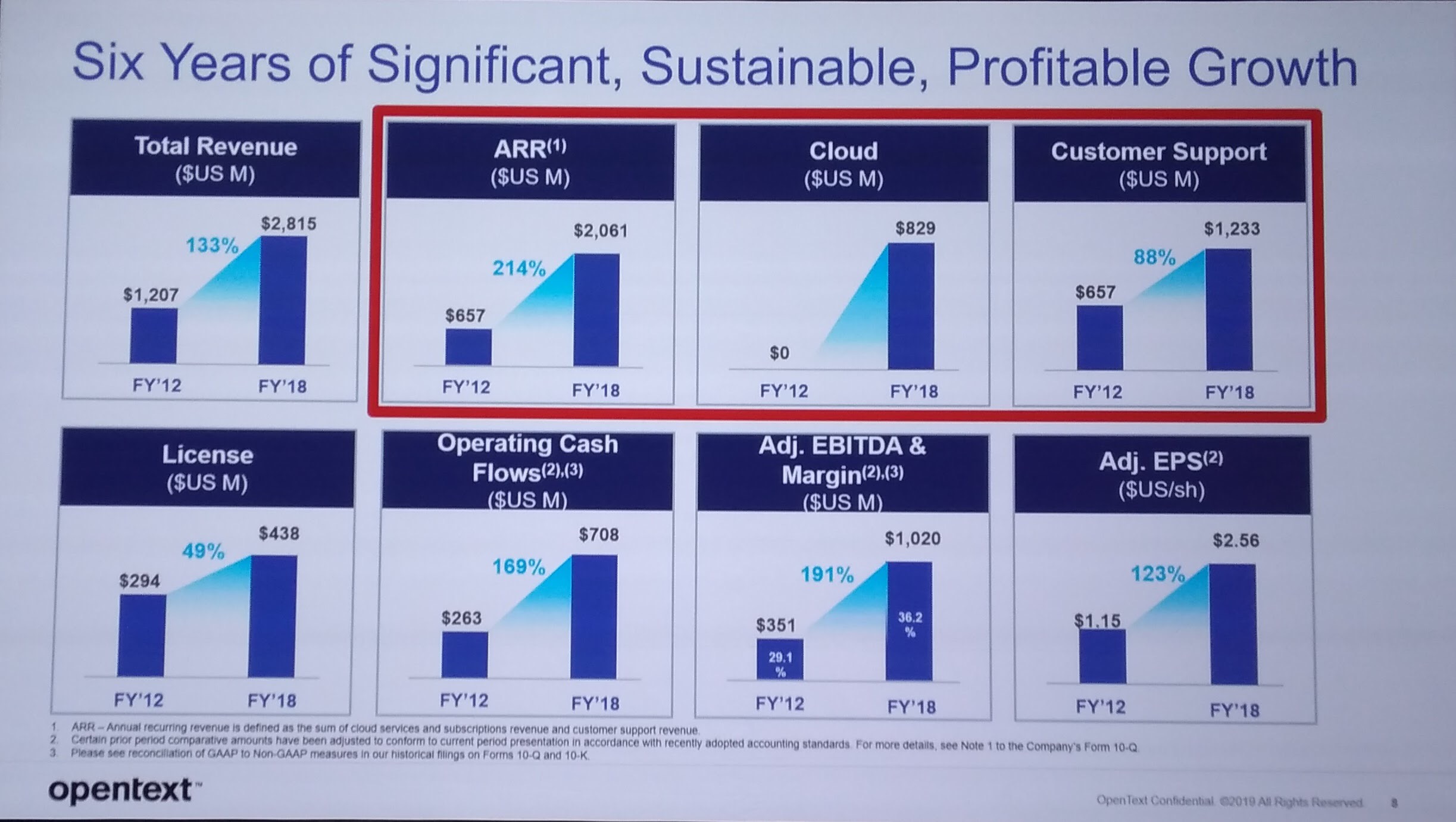
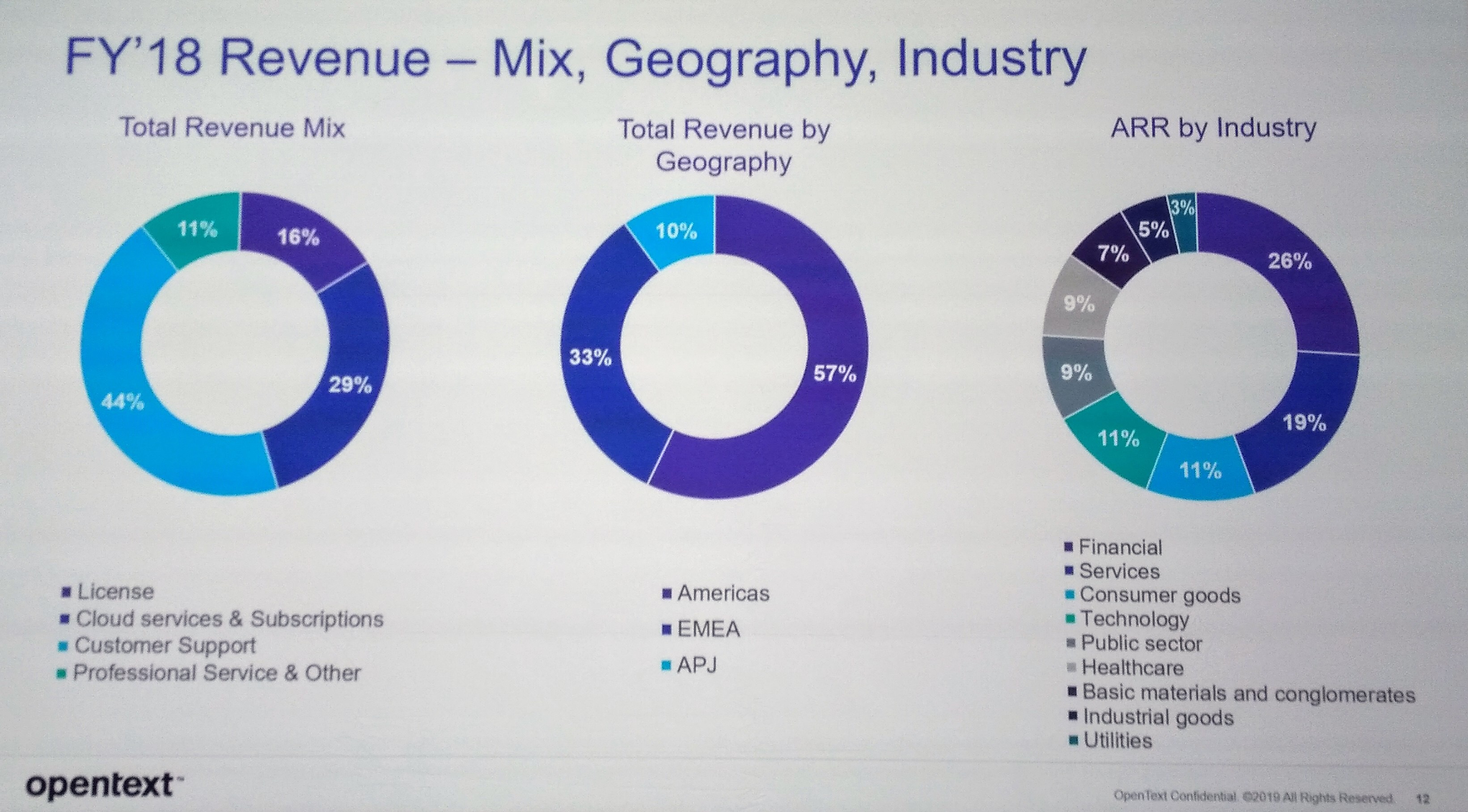
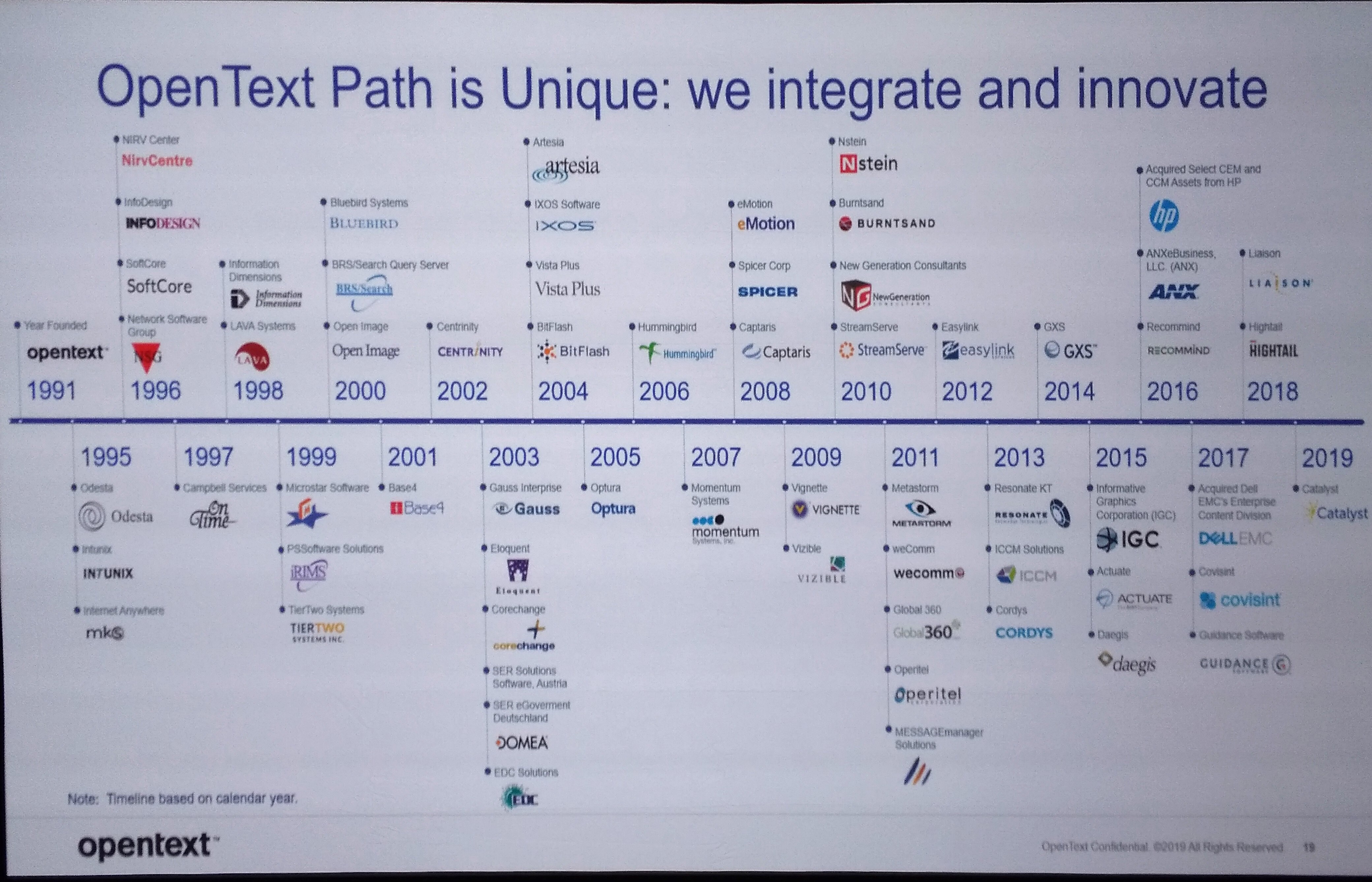
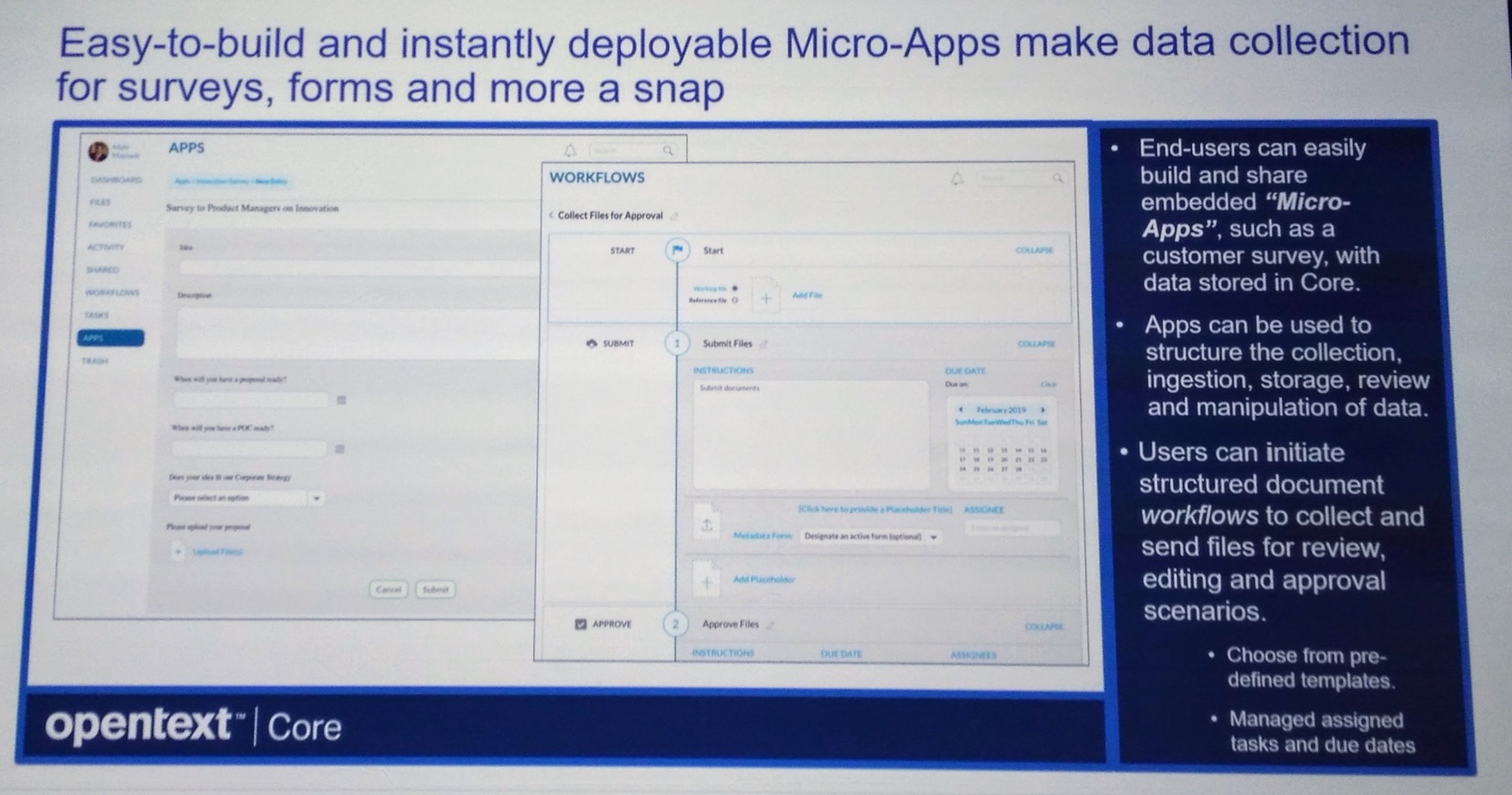
Although technically a product breakout, the session on OpenText’s Digital Accelerants product collection was presented to the entire audience as our last full-audience session before the afternoon breakouts. This was split into three sections: cloud, AI and analytics, and process automation.
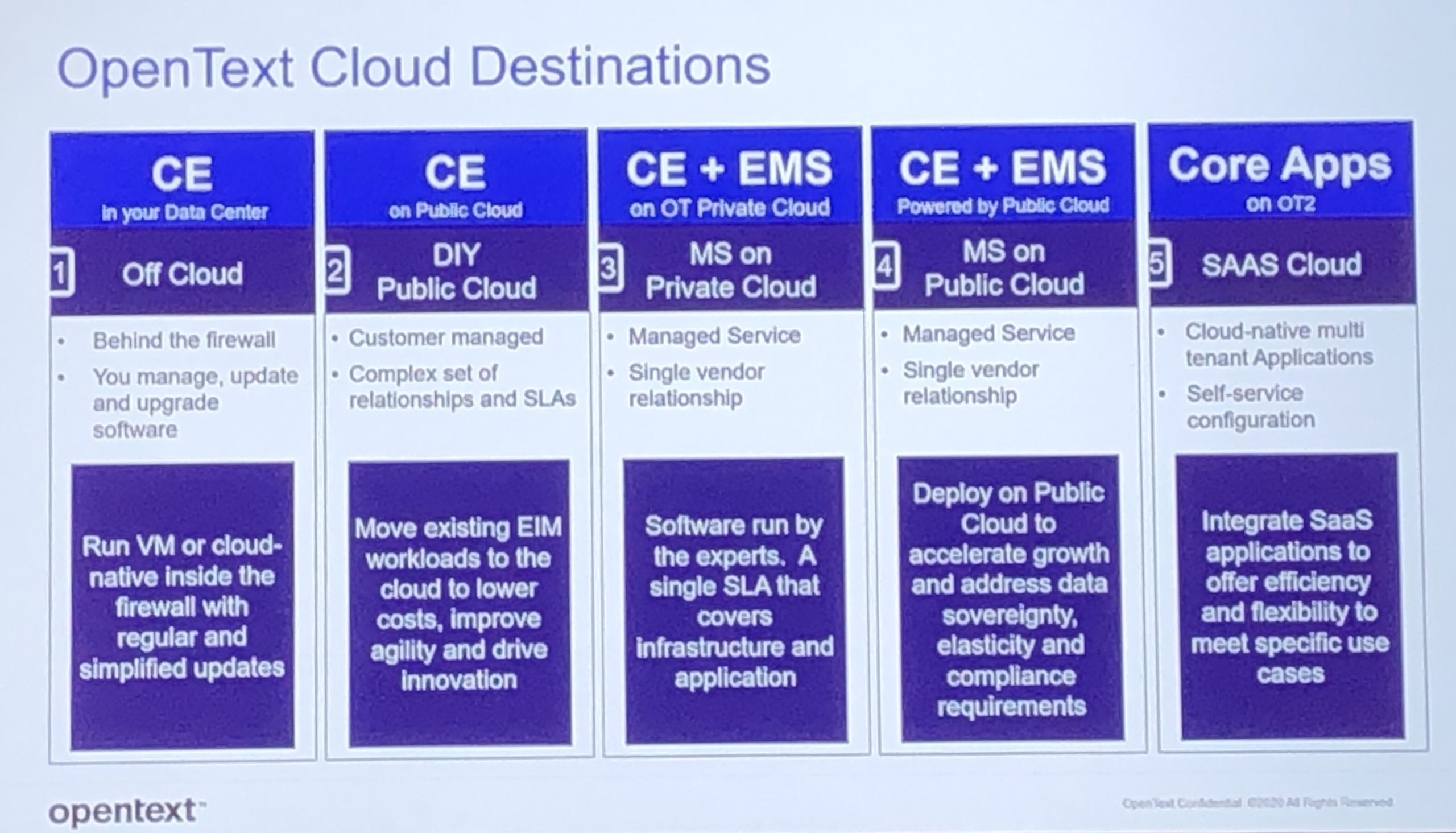
Jon Schupp, VP of Cloud GTM, spoke about how information is transforming the world: not just cloud, but a number of other technologies, a changing workforce, growing customer expectations and privacy concerns. Cloud, however, is the destination for innovation. Moving to cloud allows enterprise customers to take advantage of the latest product features, guaranteed availability, global reach and scalability while reducing their operational IT footprint. OpenText provides a number of different deployment platforms: “off-cloud” (aka on-premise), public cloud, private cloud, managed services, and SaaS.

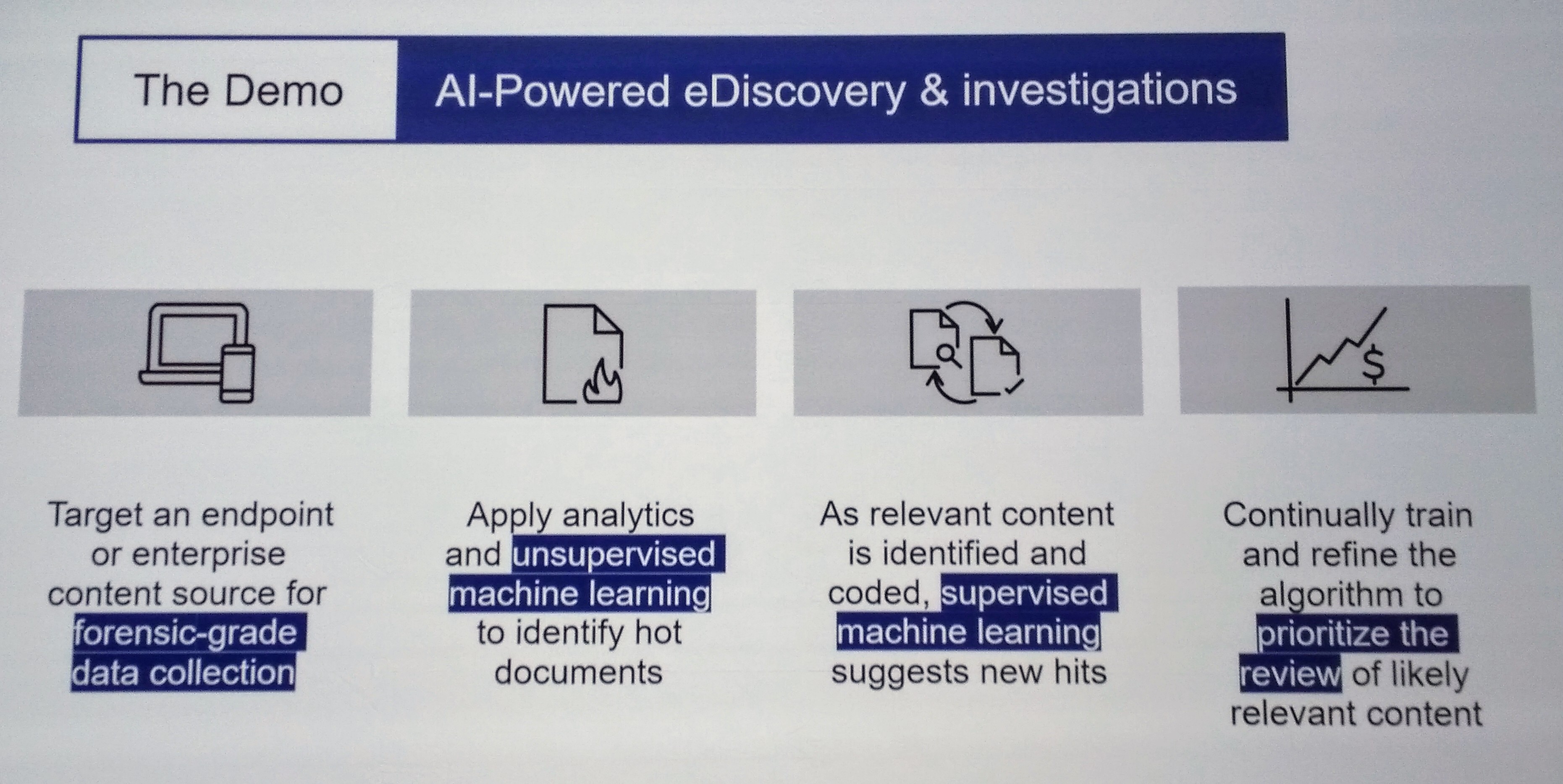
Dave Moyers and Paul O’Hagan were up next to talk about AI and analytics, and how they are addressing data variety, ease of use, embedding AI/ML in processes, and deploying anywhere that it’s required. Their AI and analytics capabilities are provided by the Magellan product, and have been integrated with other OpenText products as well as built into vertical solutions. Magellan has been integrated into the ECM products with AI-augmented capture and the AI-powered “magic folder” auto-categorization and filing; into the Business Network products with asset performance optimization and predictive maintenance; into AppWords by instantiating processes based on insights; and several other integrations. They also have some new standard features for identifying PII (personal identifiable information), which is crucial for compliance and privacy. In addition to the analysis capabilities, there is a wide range of dashboard and visualization options, and full-fledged ETL for connecting to enterprise and third-party data sources and organize data flows. We also saw some examples yesterday of using Magellan for e-discovery and sentiment analysis. Interestingly, this is one of the product portfolios where they’ve taken advantage of integrating with open source tools to extend the core products.

Saving the best for last (okay, maybe that’s just my bias), Lori McKellar and Nick King presented on business process automation. This is not just about back-office automation, but includes customer-facing processing, IoT and other more complex intelligent processes. AppWorks, which includes the process automation capabilities, is an application development environment for use by semi-technical citizen developers (low-code) as well as professional developers (pro-code). We saw the all-new developer experience last year, and now they’ve had a chance to integrate the actual customer usage to fine-tune both the developer and end-user AppWorks experience. One significant change is that as their customers start to build larger apps, they now allow more granular access to the entities under development to allow multiple developers to be working on the same application simultaneously without collisions. They’ve added some new UI capabilities, such as a card view option and an optimized tablet view. Integration with Documentum has been improved for easier document check-in and repository access. Privacy features, including dynamic instance-level permissions and document redaction, are now available in AppWorks. In the upcoming 20.2 version, they’ll be adding an RPA connector framework, then expanding the RPA integrations in 20.3.
The session finished with a Q&A with all of the participants, including discussions on RPA connectors, operationalization of machine learning, hybrid cloud models, the role of unstructured content in AI training, and natural language processing.
This afternoon, I’ll be attending the breakout session on content services, so stay tuned for those final notes from the OpenText Analyst Summit 2020.