
I know that only a small percentage of my readers are in Toronto, but if you are, and you blog, you’ll be interested in the bloggers’ dinner that is forming around Shel Israel‘s visit next Monday. Shel, the co-author of Naked Conversations, will even sign a copy of his book for you. Shoeless Joe’s, 401 King West, 6:30pm. Details here and here.
Author: sandy
Do you know the way to SOA?
It’s not often that a graphic from a vendor makes me laugh out loud, but this one from TIBCO did:

I’ll be humming Burt Bacharach tunes all afternoon.
Webinar: Taking BPM to another level
I’ve just finished listening to an ebizQ webinar How to Take BPM to Another Level in Your Organization, featuring Jim Sinur from Gartner. webMethods is the sponsor, so Susan Ganeshan, their VP of Product Development, is also on the line.
Sinur made a quick plug for the upcoming overpriced Gartner BPM summit, but then dug into some interesting material. Much of it was a duplicate of what I had seen presented by Michael Melenovsky in Toronto a few weeks ago — such as the comparison between a functionally-driven and process-driven enterprise, and the set of practices required around BPM — but it was good to see it again since I still haven’t received a set of slides from the Toronto seminar so had to rely on my rough notes. I liked the slide on the roles and responsibilities of business and IT, especially the centre column showing the shared responsibilities:
- Process deployment
- Process execution and performance
- Business and process rules analysis and management
- Operational procedures including version level control
- Creation of process, rules, and events repository
- Detailed process design
- Training and education
- Event analysis and management
This lines up with what I’m seeing with my customers, as IT relinquishes more control to the business, and the business starts to step up to the challenge in order to ensure that what gets implemented is actually what they need. I believe that the business still needs to be more proactive in this area: in the large financial institutions that I mainly work with, many parts of the business have become completely passive with respect to new technology, and just accept (while complaining) whatever is given them. I’m not in favour of giving over design control to the business, but they definitely need to be involved in this list of activities if the BPM project is going to hit the ground running.
I also liked the slide on what’s happening with rules and BPM in the context of policy-managed applications:
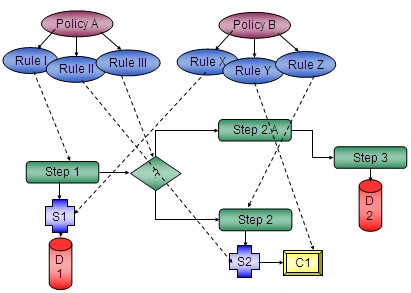
This is a very enterprise architecture-like view of the process, where you see the business policies at the top, the resultant rules immediately below that, then the linkages from the rules to the data and services at the bottom, which are in turn plugged into specific steps of the process. Making these linkages is what ultimately provides business agility, since it allows you to see what parts of the technology will be impacted by a change in a policy, or vice versa. There really needs to be more enterprise architecture modelling going on as part of most organizations, but particularly as it related to process orchestration and BPM in general.
At the 22 minute mark, Sinur returned to another 2 minutes of shameless plugging for the conference. Considering that we were just warming up for the “real” vendor to start plugging their product, the commercial content of this webinar was a bit high.
Although webMethods supposedly entered the BPM market back in 2001 on their acquisition of IntelliFrame, I’m not seeing them on any BPM radar screens — they’re really considered more of an integration suite. Ganeshan really should have practiced reading her script before she read it on the air, too, although she was much better at the Q&A. Except for the remark about how they don’t do BPMN because their customers really like webMethods’ “richer” proprietary interface instead (as if they have a choice).
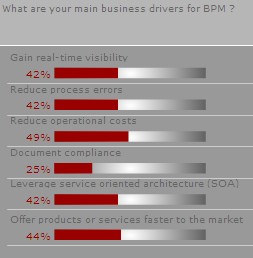 At the end, the moderator showed the results of the survey question that she had posed near the beginning of the webinar. No big surprises here, although interesting to note that all of the drivers (except for document compliance) are becoming equally important to people. The trend that I’m seeing is that the goal of improving operational efficiency (shown on this survey as “reduce operational costs” and “reduce process errors”) are being taken for granted: everyone expects that will be the result of implementing BPM, so it’s not considered the main business driver. Instead, process visibility and process orchestration are moving to the forefront, which in turn drive the agility that allows an organization to bring its products and services to market faster.
At the end, the moderator showed the results of the survey question that she had posed near the beginning of the webinar. No big surprises here, although interesting to note that all of the drivers (except for document compliance) are becoming equally important to people. The trend that I’m seeing is that the goal of improving operational efficiency (shown on this survey as “reduce operational costs” and “reduce process errors”) are being taken for granted: everyone expects that will be the result of implementing BPM, so it’s not considered the main business driver. Instead, process visibility and process orchestration are moving to the forefront, which in turn drive the agility that allows an organization to bring its products and services to market faster.
ebizQ is using some new webinar software lately (or maybe a new version) which has some nice new features. It allows you to download the presentation at any time (other webinar providers could learn a HUGE lesson from that), zoom on the slides, and other features from the previous version, but now also shows a list of upcoming webinars in the sidebar and allows you to pop up a list of the attendees (first name and company only). Unfortunately, I had some major connectivity problems that resulted in a five minute gap right at the beginning of the Q&A, so I’ll have to go back to the replay and check it out. Fortunately, they publish the replays very quickly after the event, using the original URL, another good lesson for other webinar providers.
Inside the BEA-Fuego deal
David Ogren is posting from inside Fuego on their acquisition by BEA. He promises “more details over the next couple days”.
Ovations BPM framework
Sunday night, I had dinner with Doug Reynolds from Ovations (caution: website misbehaves on Firefox), who make a .Net BPM framework that sits on top of FileNet, K2 and other BPM products. I’ve known Doug since the late 1990’s, when I owned a small SI firm and he worked at Meta Software, then through 2000-1 when I worked at FileNet and he was one of the founders of the Meta spin-off Cape Visions (now just a shell company since the technology was sold to FileNet to become the core of their Process Analyzer product). After that, we lost touch — my last memory being of drinking tequila together in a bar in Huntington Beach — until last November when we reconnected at FileNet’s user conference. He’s now the President of Ovations’ US operation (Ovations is headquartered in South Africa), building the North American market for their framework, OvaFlo (the name of which really makes me think about menstrual cycles, but never mind), and associated services.
Doug and a colleague showed up in Toronto this weekend, and we spent a good few hours in one of my favourite Ethiopian restaurants talking about Ovations’ framework, competing frameworks, hockey, BPM products, the fact that they showed up in -10C weather with no gloves, and the need for a general unified theory of BPM. Okay, I made the last one up, but we did wax a bit philosophical at times.
There’s still a need for some sort of framework in many of my customers’ implementations, especially around case management activities and, to a lesser extent, work assignment, but many of the ones that I’ve seen in the past tend to reinvent some or all of the BPM functionality within the framework, thereby cutting you off from the specific functions — and advantages — of the underlying product. Personally, I’d never recommend using a framework that completely hid the underlying product; although it might be an advantage to the framework vendor to support multiple vendors’ BPM products completely under the covers, for the customer it usually means that the framework provides only the least common denominator of functionality and contains a whole lot of other crap to not only make it vendor-independent but have it appear identical regardless of the underlying product.
The result of all this is that Doug will be giving me a remote demo sometime soon so that I can check out the framework for myself. More to come on this one.
BEA snaps up Fuego
BEA bought Fuego today, which starts to bring home the predictions about consolidation in the BPM marketplace. Press release here on ebizQ or here on the BEA site, which includes the usual hyperbole from the CEO:
We are now the only company to offer a unified SOA-based platform to integrate business processes, applications, and legacy environments.
There might be a few of BEA and Fuego’s competitors that disagree with the “only” qualifier, although this marriage of ESB, BPM and other integration technologies does provide good coverage of the space, reminiscent of the Staffware acquisition by TIBCO a few years back. Fuego will form the foundation of BEA’s new AquaLogic Business Service Integration product line, and give BEA a much better story for talking to business executives, instead of just chatting with the IT guys like they’ve been doing in the past.
This is the second key acquisition for BEA in the past year, following their acquistion of Plumtree last summer. They’re definitely building out their integration capabilities, and doing so by including products that are fairly platform-agnostic for the widest appeal. The real test will be to see how tightly this stuff is integrated a year from now: it’s not enough to just slap a BEA label on Fuego software, there needs to be technical infrastructure reasons and goals for making an acquisition like this.
One interesting thing that I noticed from the press release and the conference call is the strong link made between BPM and SOA (something that I’ve been writing about for some time). On the conference call, Mark Carges from BEA refers to BPM as “the fastest growing segment of SOA”.
You can hear a replay of the 20-minute announcement conference call at mshow using the show number 292109.
Investing in BPM webinar
Understand that first of all, I think that Bruce Silver is a very smart guy, and don’t take it the wrong way when I say that he is a less-than-scintillating speaker. He was featured on Appian‘s Investing in BPM webinar today, and his talk turned out to be just a slight expansion of his Intelligent Enterprise article that I discussed earlier; it wasn’t exactly edge-of-the-seat stuff. Maybe he should spend less of his time reading from a script, and more just talking about this subject matter that he knows so well. And although he was giving a beginner’s guide to BPM, I have a bit of a problem with him starting out his talk with “I want to talk to you about a new kind of software, business process management…” New kind of software? Not.
 After the requisite 20 minutes of “independent content” that the vendors use to hook you into attending their webinars, Appian’s Director of Product Management, Phil Larson, stepped in and talked more about BPM in general and about their product. He was interesting enough to keep me on the line for the remainder of the webinar, and he had good illustrations of some of the concepts, including the prettiest diagram that I’ve seen to show how BPM and SOA fit together. Not the most complete, but sometimes you just need a pretty version to make your point.
After the requisite 20 minutes of “independent content” that the vendors use to hook you into attending their webinars, Appian’s Director of Product Management, Phil Larson, stepped in and talked more about BPM in general and about their product. He was interesting enough to keep me on the line for the remainder of the webinar, and he had good illustrations of some of the concepts, including the prettiest diagram that I’ve seen to show how BPM and SOA fit together. Not the most complete, but sometimes you just need a pretty version to make your point.
 Larson quoted from the recent Forrester report — “[Appian] has the widest breadth of functionality among the suites we evaluated” — although he didn’t mention the bit that came later in the same paragraph of the report: “However, breadth comes at the expense of depth in features like simulation and system-to-system integration“. He showed a snap of their BPMN implementation, which gets good marks off the bat for having the swimlanes running in the right direction.
Larson quoted from the recent Forrester report — “[Appian] has the widest breadth of functionality among the suites we evaluated” — although he didn’t mention the bit that came later in the same paragraph of the report: “However, breadth comes at the expense of depth in features like simulation and system-to-system integration“. He showed a snap of their BPMN implementation, which gets good marks off the bat for having the swimlanes running in the right direction.
I’m not sure if Appian will have the webinar available for replay later, although it’s not really worth it unless you’re a true beginner. I think that you can get most of the information from Silver’s portion of the talk from the earlier-reference Intelligent Enterprise article, and most of the Appian information from their web site.
ScrAPI series
The first of a series of posts on scrAPIs (which I commented on following Mashup Camp last week) by Thor Muller of Rubyred Labs. I’m looking forward to the rest of the series this week.
Forrester Wave for Human-Centric BPMS
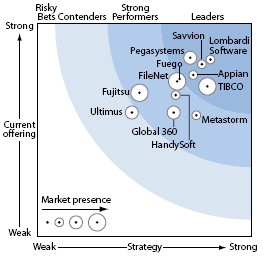 Forrester just released a report on human-centric BPMS, and Lombardi is just busting with pride over their position: so much so, that they’re giving the report away here (registration required). Phil Gilbert must be doing a little happy dance, especially considering that their “dot size” has increased from a tiny blip on the radar to a more respectable market presence. Forrester’s had a soft spot for Lombardi for a while: the March 2004 “Pure Play BPM” wave (that’s when we were still calling this “pure play”) had Lombardi at the cusp between Strong Performer and Leader. Relative positions of many players have stayed pretty much the same since then in the Forrester rankings (Garter’s rankings are quite different), although TIBCO and Pegasystems have made significant increases in market presence. I’d have to say that Forrester must have been looking mostly at the American market presence, since TIBCO (which was still the Staffware product during the 2004 ranking) had a huge presence in UK, European, Australian and other markets that I saw.
Forrester just released a report on human-centric BPMS, and Lombardi is just busting with pride over their position: so much so, that they’re giving the report away here (registration required). Phil Gilbert must be doing a little happy dance, especially considering that their “dot size” has increased from a tiny blip on the radar to a more respectable market presence. Forrester’s had a soft spot for Lombardi for a while: the March 2004 “Pure Play BPM” wave (that’s when we were still calling this “pure play”) had Lombardi at the cusp between Strong Performer and Leader. Relative positions of many players have stayed pretty much the same since then in the Forrester rankings (Garter’s rankings are quite different), although TIBCO and Pegasystems have made significant increases in market presence. I’d have to say that Forrester must have been looking mostly at the American market presence, since TIBCO (which was still the Staffware product during the 2004 ranking) had a huge presence in UK, European, Australian and other markets that I saw.
Excerpts from Forrester’s executive summary regarding those in the Leaders category:
Lombardi Software, Pegasystems, and Savvion lead with comprehensive suites that foster rapid, iterative process design; Appian leads with a richly featured suite for people-intensive work; and TIBCO leads with a human-centric BPMS that leverages its integration-centric product.
In fact, later in the report, they more categorically state “Lombardi Software, Pegasystems, and Savvion lead the pack — hands down“, then they proceed to break out the specific reasons for their evaluation. However, they also stated “If you could only buy one BPMS product, Fuego offers the best — bar none — product supporting human-intensive and system-intensive processes“, an assessment with which I don’t disagree, after seeing things like Fuego’s web services introspection (although I still insist that they put their swimlanes sideways). They go on to say that “Appian and FileNet innovate beyond the boundaries of human-centric BPMS” by integrating collaboration tools that allow a non-standard process to go off the rails in a somewhat controlled manner.
One thing I didn’t like is how Forrester categorizes business processes:
- Integration-intensive
- People-intensive
- Decision-intensive
- Document-intensive
I don’t really agree with this categorization, first of all since it’s not normalized: integration-intensive and people-intensive certainly are at opposite ends of the same scale, but their definition of decision-intensive is really people-intensive with a strong need for business rules (which I think are necessary pretty much all the time), and document-intensive is just people-intensive with a lot of scanned documents involved. Although document-intensive processes would always be people-intensive, I believe that decision-intensive could fall anywhere along the integration-to-people scale since it is primarily about the use of business rules. Although many organizations are still choosing separate products for integration-intensive and people-intensive (or human-interrupted, as one of my customers once so charmingly put it) processes, the real issue in this report should be about any given product handles all three of (what I see the artificial divisions of) people-, decision- and document-intensive functionality.
The last half of the report shows the explicit criteria ranking for each vendor, and a detailed paragraph of strengths and weaknesses for each vendor. Definitely worth the read.
Update on BPM Think Tank
 Further to my initial post on OMG’s BPM Think Tank coming up on May 23-25, it’s now open for registration. There’s one day of pre-conference workshops, then two days of conference, including four sessions of executive and technology roundtables. Looks to be more interactive than your average conference.
Further to my initial post on OMG’s BPM Think Tank coming up on May 23-25, it’s now open for registration. There’s one day of pre-conference workshops, then two days of conference, including four sessions of executive and technology roundtables. Looks to be more interactive than your average conference.
Book by May 1st for early-bird discount pricing.