I gave a webinar last week, sponsored by TIBCO, on business process modeling; you’ll be able to find a replay of the webinar, complete with the slides, here). Here’s the questions that we received during the webinar and I didn’t have time to answer on the air:
Q: Any special considerations for “long-running” processes – tasks that take weeks or months to complete?
A: For modeling long-running processes, there’s a few considerations. You need to be sure that you’re capturing sufficient information in the process model to allow the processes to be monitored adequately, since these processes may represent risk or revenue that must be accounted for in some way. Second, you need to ensure that you’re building in the right triggers to release the processes from any hold state, and that there’s some sort of manual override if a process needs to be released from the hold state early due to unforeseen events. Third, you need to consider what happens when your process model changes while processes are in flight, and whether those processes need to be updated to the new process model or continue on their existing path; this may require some decisions within the process that are based on a process version, for example.
Q: Do you have a recommendation for a requirements framework that guides analysts on these considerations, e.g. PRINCE2?
A: I find most of the existing requirements frameworks, such as use cases, to be not oriented enough towards processes to be of much use with business process modeling. PRINCE2 is a project management methodology, not a requirements framework.
Q: The main value proposition of SOA is widely believed to be service reuse. Some of the early adopters of SOA, though, have stated that they are only reusing a small number of services. Does this impact the value of the investment?
A: There’s been a lot written about the “myth” of service reuse, and it has proved to be more elusive than many people thought. There’s a few different philosophies towards service design that are likely impacting the level of reuse: some people believe in building all the services first, in isolation of any calling applications, whereas others believe in only building services that are required to meet a specific application’s needs. If you do the former, then there’s a chance that you will build services that no one actually needs — unlike Field of Dreams, if you build it, they may not come. If you do the latter, then your chance of service reuse is greatly reduced, since you’re effectively building single-purpose services that will be useful to another application only by chance.
The best method is more of a hybrid approach: start with a general understanding of the services required by your key applications, and use apply some good old-fashioned architectural/design common sense to map out a set of services that will maximize reusability without placing an undue burden on the calling applications. By considering the requirements of more than one application during this exercise, you will at least be forcing yourself to consider some level of reusability. There’s a lot of arguments about how granular is too granular for services; again, that’s mostly a matter that can be resolved with some design/development experience and some common sense. It’s not, for that matter, fundamentally different than developing libraries of functions like we used to do in code (okay, like I used to do in code) — it’s only the calling mechanism that’s different, but the principles of reusability and granularity have not changed. If you designed and build reusable function libraries in the past, then you probably have a lot of the knowledge that you need to design — at least at a conceptual level — reusable services. If you haven’t built reusable function libraries or services in the past, then find yourself a computer science major or computer engineer who has.
Once you have your base library of services, things start getting more interesting, since you need to make sure that you’re not rewriting services that already exist for each new application. That means that the services must be properly documented so that application designers and analysts are aware of their existence and functionality; they must provide backwards compatibility so that if new functionality is added into a service, it still works for existing applications that call it (without modifying or recompiling those applications); and most important of all, the team responsible for maintaining and creating new services must be agile enough to be able to respond to the requirements of application architects/designers who need new or modified services.
As I mentioned on the webinar, SOA is a great idea but it’s hard to justify the cost unless you have a “killer application” like BPM that makes use of the services.
Q: Can the service discovery part be completely automated… meaning no human interaction? Not just discovery, but service usage as well?
A: If services are registered in a directory (e.g., UDDI), then theoretically it’s possible to discover and use them in an automated fashion, although the difficultly lies in determining which service parameters are mapped to which internal parameters in the calling application. It may be possible to make some of these connections based on name and parameter type, but every BPMS that I’ve seen requires that you manually hook up services to the process data fields at the point that the service is called.
Q: I’d be interested to know if you’re aware of a solid intro or training in the use and application of BPMN. I’ve only found general intros that tend to use the examples in the standard.
A: Bruce Silver offers a comprehensive course in BPMN, which I believe it available as either an online or classroom course.
Q: Does Data Object mean adding external documentation like a Word document into the BPM flow?
A: The origin of the data object is, in part, to serve the requirements of document-centric BPM, where the data object may represent a document (electronic, scanned paper, or a physical paper document) that travels with the workflow. Data objects can be associated with a sequence flow object — the arrows that indicate the flow in a process map — to show that the data artifact moves along that path, or can be shown as inputs and outputs to a process to show that the process acts on that data object. In general, the data object would not be documentation about the process, but would be specific to each instance of the process.
Q: Where is the BPMN standard found?
A: BPMN is now maintained by OMG, although they link through to the original BPMN website still.
Q: What is the output of a BPMN process definition? Any standard file types?
A: BPMN does not specify a file type, and as I mentioned in the webinar, there are three main file formats that may be used. The most commonly used by BPA and BPM vendors, including TIBCO, is XPDL (XML Process Definition Language) from the Workflow Management Coalition. BPEL (Business Process Execution Language) from OASIS has gained popularity in the past year or so, but since it was originally designed as a web service orchestration language, it doesn’t include support all of the BPMN constructs so there may be some loss of information when mapping from BPMN into BPEL. BPDM (Business Process Definition Metamodel), a soon-to-be-released standard from OMG, promises to do everything that XPDL does and more, although it will be a while before the level of adoption nears that of XPDL.
Q: What’s the proper perspective BPM implementers should have on BPMN, XPDL, BPEL, BPEL4People, and BPDM?
A: To sum up from the previous answer: BPMN is the only real contender as a process notation standard, and should be used whenever possible; XPDL is the current de facto standard for interchange of BPMN models between tools; BPDM is an emerging standard to watch that may eventually replace XPDL; BPEL is a web service orchestration language (rarely actually used as an execution language in spite of its name); and BPEL4People is a proposed extension to BPEL that’s trying to add in the ability to handle human-facing tasks, and the only standard that universally causes laughter when I name it aloud. This is, of course, my opinion; people from the integration camp will disagree — likely quite vociferously — with my characterization of BPEL, and those behind the BPDM standard will encourage us all to cast out our XPDL and convert immediately. Realistically, however, XPDL is here to stay for a while as an interchange format, and if you’re modeling with BPMN, then your tools should support XPDL if you plan to exchange process models between tools.
I’m headed for the BPM Think Tank next week, where all of these standards will be discussed, so stay tuned for more information.
Q: How would one link the business processes to the data elements or would this be a different artifact altogether?
A: The BPMN standard allows for the modeler to define custom properties, or data elements, with the scope depending on where the properties are defined: when defined at the process level, the properties are available to the tasks, objects and subprocesses within that process; when defined at the activity level, they’re local to that activity.
Q: I’ve seen some swim lane diagrams that confuse more than illuminate – lacking specific BPMN rules, do you have any personal usage recommendations?
A: Hard to say, unless you state what in particular that you find confusing. Sometimes there is a tendency to try to put everything in one process map instead of using subprocesses to simplify things — an overly-cluttered map is bound to be confusing. I’d recommend a high-level process map with a relatively small number of steps and few explicit data objects to show the overall process flow, where each of those steps might drill down into a subprocess for more detail.
Q: We’ve had problems in the past trying to model business processes at a level that’s too granular. We ended up making a distinction between workflow and screen flow. How would you determine the appropriate level of modeling in BPM?
A: This is likely asking a similar question to the previous one, that is, how to keep process maps from becoming too confusing, which is usually a result of too much detail in a single map. I have a lot of trouble with the concept of “screen flow” as it pertains to process modeling, since you should be modeling tasks, not system screens: including the screens in your process model implies that there’s not another way to do this, when in fact there may be a way to automate some steps that will completely eliminate the use of some screens. In general, I would model human tasks at a level where a task is done by a single person and represents some sort of atomic function that can’t be split between multiple people; a task may require that several screens be visited on a legacy system.
For example, in mutual funds transaction processing (a particular favorite of mine), there is usually a task “process purchase transaction” that indicates that a person enters the mutual fund purchase information to their transaction processing system. In one case, that might mean that they visit three different green screens on their legacy system. Or, if someone wrote a nice front-end to the legacy system, it might mean that they use a single graphical screen to enter all the data, which pushes it to the legacy system in the background. In both cases, the business process is the same, and should be modeled as such. The specific screens that they visit at that task in order to complete the task — i.e., the “screen flow” — shouldn’t be modeled as explicit separate steps, but would exist as documentation for how to execute that particular step.
Q: The military loves to be able to do self-service, can you elaborate on what is possible with that?
A: Military self-service, as in “the military just helped themselves to Poland?” 🙂 Seriously, BPM can enable self-service because it allows anyone to participate in part of a process while monitoring what’s happening at any given step. That allows you to create steps that flow out to anyone in the organization or even, with appropriate network security, to external contractors or other participants. I spoke in the webinar about creating process improvement by disintermediation; this is exactly what I was referring to, since you can remove the middle-man by allowing someone to participate directly in the process.
Q: In the real world, how reliable are business process simulations in predicting actual cycle times and throughput?
A: (From Emily) It really depends on the accuracy of your information about the averages of your cycles. If they are relatively accurate, then it can be useful. Additionally, simulation can be useful in helping you to identify potential problems, e.g. breakpoints of volume that cause significant bottlenecks given your average cycle times.
I would add that one of the most difficult things to estimate is the arrival time of new process instances, since rarely do they follow those nice even distributions that you see when vendors demonstrate simulation. If you can use actual historical data for arrivals in the simulation, it will improve the accuracy considerably.
Q: Would you have multiple lanes for one system? i.e. a legacy that has many applications in it therefore many lanes in the legacy pool ?
A: It depends on how granular that you want to be in modeling your systems, and whether the multiple systems are relevant to the process analysis efforts. If you’re looking to replace some of those systems as part of the improvement efforts, or if you need to model the interactions between the systems, then definitely model them separately. If the applications are treated as a single monolithic system for the purposes of the analysis, then you may not need to break them out.
Q: Do you initially model the current process as-is in the modeling tool?
A: I would recommend that you at least do some high-level process modeling of your existing process. First of all, you need to establish what the metrics are that you’re establishing for your ROI, and often these aren’t evident until you map out your process. Secondly, you may want to run simulations in the modeling tool on the existing process to verify your assumptions about the bottlenecks and costs of the process, and to establish a baseline against which to compare the future-state process.
Q: Business Managers : concerns – failure to achieve ROI ?
A: I’m not exactly sure what this question means, but assume that it relates to the slide near the end of the webinar that discusses role changes caused by BPM. Management and executives are most concerned with risk around a project, and they may have concerns that the ROI is too ambitious (either because the new technology fails or too many “soft” ROI factors were used in the calculation) and that the BPM project will fail to meet the promises that they’ve likely made to the layers of management above them. The right choice of ROI metrics can go a long ways to calming their fears, and educating them on the significant benefits of process governance that will result from the implementation of BPM. Management will now have an unprecedented view of the current state and performance of the end-to-end process. They’ll also have more comprehensive departmental performance statistics without manual logging or cutting and pasting from several team reports.
Q: I am a manager in a MNC and I wanted to know how this can help me in my management. How can I use it in my daily management? One example please?
A: By “MNC” I assume that you mean “multi-national corporation”. The answer is no different than from any other type of organization, except that you’re likely to be collaborating with other parts of your organization in other countries hence have the potential to see even greater benefits. One key area for improvement that can be identified with business process modeling, then implemented in a BPMS, is all of the functional redundancy that typically occurs in multi-nationals, particularly those that grow by acquisition. Many functional areas, both administrative/support and line-of-business, will be repeated in multiple locations, for no better reason than that it wasn’t possible to combine them before technology was brought to bear on it. Process modeling will allow you to identify areas that have the potential to be combined across different geographies, and BPM technology allows processes to flow seamlessly from one location to another.
Q: How much detail is allowed in a process diagram (such as the name of the supplier used in a purchase order process or if the manager should be notified via email or SMS to approve a loan)? Is process visibility preferred compared to good classic technical design, in the BPM world?
A: A placeholder for the name of a supplier would certainly be modeled using a property of the process, as would any other custom data elements. As for the channel used for notifying the manager, that might be something that the manager can select himself (optimally) rather than having that fixed by the process; I would consider that to be more of an implementation detail although it could be included in the process model.
I find your second question interesting, because it implies that there’s somehow a conflict between good design and process visibility. Good design starts with the high-level process functional design, which is the job of the analyst who’s doing the process modeling; this person needs to have analytical and design skills even though it’s unlikely that they do technical design or write code. Process visibility usually refers to the ability of people to see what’s happening within executing processes, which would definitely be the result of a good design, as opposed to something that has to be traded off against good design. I might be missing the point of your question, feel free to add a comment to clarify.
Q: Are there any frameworks to develop a BPM solution?
A: Typically, the use of a BPMS implies (or imposes) a framework of sorts on your BPM implementation. For example, you’re using their modeling tool to draw out your process map, which creates all the underpinnings of the executable process without you writing any code to do so. Similarly, you typically use a graphical mapping functionality to map the process parameters onto web services parameters, which in turn creates the technical linkages. Since you’re working in a near-zero-code environment, there’s no real technical framework involved beyond the BPMS itself. I have seen cases where misguided systems integrators create large “frameworks” — actually custom solutions that always require a great deal of additional customization — on top of a BPMS that tends to demote the BPMS to a simple queuing system. Not recommended.
There were also a few questions specifically about TIBCO, for which Emily Burns (TIBCO’s marketing manager, who moderated the webinar) provided answers:
Q: Is TIBCO Studio compatible with Windows Vista?
A: No, Vista is not yet supported.
Q: Are there some examples of ROI from the industry verticals
A: On TIBCO’s web site, there are a variety of case studies that discuss ROI here: http://www.tibco.com/solutions/bpm/customers.jsp. Additionally, these are broken down into some of the major verticals here: http://www.tibco.com/solutions/bpm/bpm_your_industry.jsp
Q: Is there any kind of repository or library of “typical” process? I’m particularly interested in clinical trials.
A: TIBCO’s modeling product ships with a large variety of sample processes aggregated by industry.
And lastly, my own personal favorite question and answer, answered by Emily:
Q: What’s the TLA for BPM+SOA?
A: RAD 🙂

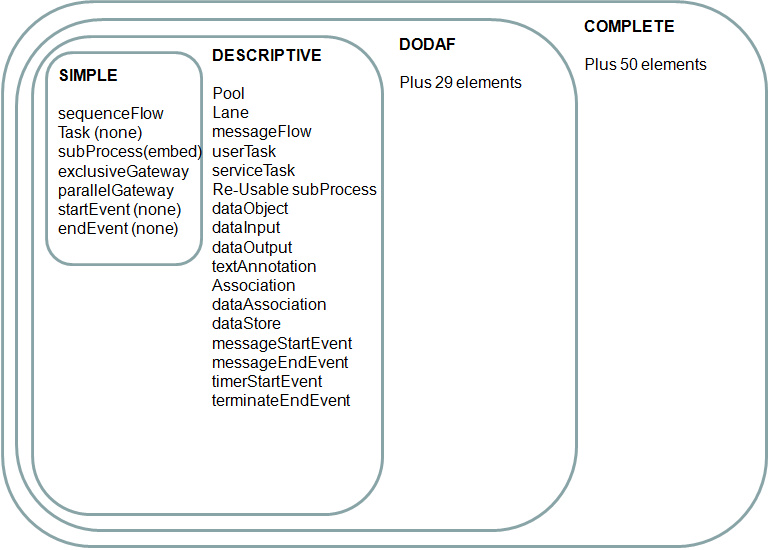 The concept of subclasses in process modeling has been included in this version, where there is a simple subset of eight elements used for process capture by non-technical process analysts/owners (start, end, sequence flow, task, subprocess, expanded subprocess, exclusive gateway, parallel gateway), then a larger subset for a “descriptive” persona, a larger-still subset for a “DODAF” persona, then the entire set of more than 100 elements.
The concept of subclasses in process modeling has been included in this version, where there is a simple subset of eight elements used for process capture by non-technical process analysts/owners (start, end, sequence flow, task, subprocess, expanded subprocess, exclusive gateway, parallel gateway), then a larger subset for a “descriptive” persona, a larger-still subset for a “DODAF” persona, then the entire set of more than 100 elements.