
There are definitely changes afoot in the open source BPM market, with both Alfresco’s Activiti and camunda releasing out-of-the-box end-user interfaces and model-driven development tools to augment their usual [Java] developer-friendly approach. In both cases, they are targeting “citizen developers”: people who have technical skills and do some amount of development, but in languages lighter weight than Java. There are a lot of people who fall into this category, including those (like me) who used to be hard-core developers but fell out of practice, and those who have little formal training in software development but have some other form of scientific or technical background.
Prior to this year, Activiti BPM was not available as a standalone commercial product from Alfresco, only bundled with Alfresco or as the community open source edition; as I discussed last year, their main push was to position Activiti as the human-centric workflow within their ECM platform. However, Activiti sports a solid BPMN engine that can be used for more than just document routing and lifecycle management, and in May Alfresco released a commercially-supported Alfresco Activiti product, although focused on the human-centric BPM market. This provides them with opportunities to monetize the existing Activiti community, as well as evolving the BPM platform independently of their ECM platform, such as providing cloud and hybrid services; however, it may have some impact on their partners who were relying on support revenue for the community version.
The open source community engine remains the core of the commercial product – in fact, the enterprise release of the engine lags behind the community release, as it should – but the commercial offering adds all of the UI tools for design, administration and end-user interface, plus cluster configuration for the execution engine.
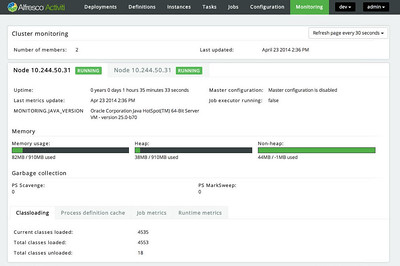 The Activiti Administrator is an on-premise web application for managing clusters, deploying process models from local packages or the Activiti Editor, and technical monitoring and administration of in-flight processes. There’s a nice setup wizard for new clusters – the open source version requires manual configuration of each node – and allows nodes within the cluster to be auto-discovered and monitored. The monitoring of process instances allows drilling into processes to see variables, the in-flight process model, and more. Not a business monitoring tool, but seems like a solid technical monitoring tool for on-premise Activiti Enterprise servers.
The Activiti Administrator is an on-premise web application for managing clusters, deploying process models from local packages or the Activiti Editor, and technical monitoring and administration of in-flight processes. There’s a nice setup wizard for new clusters – the open source version requires manual configuration of each node – and allows nodes within the cluster to be auto-discovered and monitored. The monitoring of process instances allows drilling into processes to see variables, the in-flight process model, and more. Not a business monitoring tool, but seems like a solid technical monitoring tool for on-premise Activiti Enterprise servers.
The Activiti Editor is a web-based BPMN process modeling environment that is a reimplementation of other open-source tools, refactored with JavaScript libraries for better performance. The palette can be configured based on the user profile in order to restrict the environment, which would typically be used to limit the number of BPMN objects available for modeling in order to reduce complexity for certain business users to create simple models; a nice feature for companies that want to OEM this into a larger environment. Models can be shared for comments (in a history stream format), versioned, then accessed from the Eclipse plug-in to create more technical executable models. Although I saw this as a standalone web app back in April, it is now integrated as the Visual Editor portion of Kickstart within the Activiti Suite.
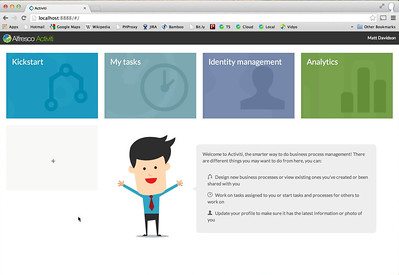 The Activiti Suite is a web application that brings together several applications into a single portal:
The Activiti Suite is a web application that brings together several applications into a single portal:
- Kickstart is their citizen development environment, providing a simple step editor that generates BPMN 2.0 – which can then be refined further using the full BPMN Visual Editor or imported into the Eclipse-based Activiti Designer – plus a reusable forms library and the ability to bundles processes into a single process application for publishing within the Suite. In the SaaS version, it will integrate with cloud services including Google Drive, Alfresco, Salesforce, Dropbox and Box.
- Tasks is the end-user interface for starting, tracking and participating in processes. It provides an inbox and other task lists, and provides for task collaboration by allowing a task recipient to add others who can then view and comment on the task. Written in Angular JS.
- Profile Management to , for user profile and administration
- Analytics, for process statistics and reports.
The Suite is not fully responsive and doesn’t have a mobile version, although apparently there are mobile solutions on the way. Since BP3 is an Activiti partner, some of the Brazos tooling is available already, and I suspect that more mobile support may be on the way from BP3 or Alfresco directly.
They have also partnered with Fluxicon to integrate process mining, allowing for introspection of the Activiti BPM history logs; I think that this is still a bit ahead of the market for most process analysts but will make it easy when they are ready to start doing process discovery for bottlenecks and outliers.
I played around with the cloud version, and it was pretty easy to use (I even found a few bugs ![]() ) and it would be usable by someone with some process modeling and lightweight development skills to build apps. The Step Editor provides a non-BPMN flowcharting style that includes a limited number of functions, but certainly enough to build functional human-centric apps: implicit process instance data definition via graphical forms design; step types for human, email, “choice” (gateway), sub-process and publishing to Alfresco Cloud; a large variety of form field types; and timeouts on human tasks (although timers based on business days, rather than calendar days, are not there yet). The BPMN Editor has a pretty complete palette of BPMN objects if you want to do a more technical model that includes service tasks and a large variety of events.
) and it would be usable by someone with some process modeling and lightweight development skills to build apps. The Step Editor provides a non-BPMN flowcharting style that includes a limited number of functions, but certainly enough to build functional human-centric apps: implicit process instance data definition via graphical forms design; step types for human, email, “choice” (gateway), sub-process and publishing to Alfresco Cloud; a large variety of form field types; and timeouts on human tasks (although timers based on business days, rather than calendar days, are not there yet). The BPMN Editor has a pretty complete palette of BPMN objects if you want to do a more technical model that includes service tasks and a large variety of events.
Although initially launched in a public cloud version, everything is also available on premise as of the end of November. They have pricing for departmental (single-server up to four cores with a limit on active processes) and enterprise (eight cores over any number of servers, with additional core licensing available) configurations, and subscription licensing for the on-premise versions of Kickstart and Administrator. The cloud version is all subscription pricing. It seems that the target is really for hybrid BPM usage, with processes living on premise or in the cloud depending on the access and security requirements. Also, with the focus on integration with content and human-centric processes, they are well-positioned to make a play in the content-centric case management space.
Instead of just being an accelerator for adding process management to Java development projects, we’re now seeing open source BPM tools like Activiti being positioned as accelerators for lighter-weight development of situational applications. This is going to open up an entire new market for them: an opportunity, but also some serious new competition.
