
We’re at the final day of the AIIM 2018 conference, and the morning keynote is with Mike Walsh, talking about business transformation and what you need to think about as you’re moving forward. He noted that businesses don’t need to worry about millenials, they need to worry about 8-year-olds: these days 90% of all 2-year-olds (in the US) know how to use a smart device, making them the truly born-digital generation. What will they expect from the companies of the future?
Machine learning allows us to customize experiences for every user and every consumer, based on analysis of content and data. Consumers will expect organizations to predict their needs, before they could even voice it themselves. In order to do that, organizations need to become algorithmic businesses: be business machines rather than have business models. Voice interaction is becoming ubiquitous, with smart devices listening to us most (all) of the time and using that to gather more data on us. Face recognition will become your de facto password, which is great if you’re unlocking your iPhone X, but maybe not so great if you don’t like public surveillance that can track your every move. Apps are becoming nagging persuaders, telling us to move more, drink more water, or attend this morning’s keynote. Like migratory birds that can sense magnetic north, we are living in a soup of smart data that guides us. Those persuasive recommendations become better at predicting our needs, and more personalized.
Although he started by saying that we don’t need to worry about millenials, 20 minutes into his presentation Walsh is admonishing us to let the youngest members of our team “do stuff rather than just get coffee”. It’s been a while since I worked in a regular office, but do people still have younger people get coffee for them?
He pointed out that rigid processes are not good, but that we need to be performance-driven rather than process-driven: making good decisions in ambiguous conditions in order to solve new problems for customers. Find people who are energized by unknowns to drive your innovation — this advice is definitely more important than considering the age of the person involved. Bring people together in the physical realm (no more work from home) if you want the ideas to spark. Take a look at your corporate culture, and gather data about how your own teams work in order to understand how employees use information and work with each other. If possible, use data and AI as the input when designing new products for customers. He recommended a next action of quantifying what high performance looks like in your organization, then work with high performers to understand how they work and collaborate.
 He discussed the myth of the simple relationship between automation and employment, and how automating a task does not, in general, put people out of work, but just changes what their job is. People working together with the automation make for more streamlined (automated) standard processes with the people focused on the things that they’re best at: handling exceptions, building relationships, making complex decision, and innovating through the lens of combining human complexity with computational thinking.
He discussed the myth of the simple relationship between automation and employment, and how automating a task does not, in general, put people out of work, but just changes what their job is. People working together with the automation make for more streamlined (automated) standard processes with the people focused on the things that they’re best at: handling exceptions, building relationships, making complex decision, and innovating through the lens of combining human complexity with computational thinking.
In summary, the new AI era means that digital leaders need to make data a strategic focus, get smart about decisions, and design work rather than doing it. Review decisions made in your organization, and decide which are best made using human insight, and which are better to automate — either way, these could become a competitive differentiator.
 Abdul and his team have built a smart healthcare suite of applications that are based on a broad foundation of data sources: he sees the data as being key, since you can’t look for patterns or detect early symptoms without the data on which to apply the intelligent algorithms. With aggregate data from a wider population and specific data for a patient, intelligent healthcare can provide much more personalized, targeted recommendations for each individual. They’ve made a number of meaningful breakthroughs in applying AI technologies to healthcare services, such as identifying gaps in care based on treatment codes, and doing real-time monitoring and intervention via IoT devices such as fitness trackers.
Abdul and his team have built a smart healthcare suite of applications that are based on a broad foundation of data sources: he sees the data as being key, since you can’t look for patterns or detect early symptoms without the data on which to apply the intelligent algorithms. With aggregate data from a wider population and specific data for a patient, intelligent healthcare can provide much more personalized, targeted recommendations for each individual. They’ve made a number of meaningful breakthroughs in applying AI technologies to healthcare services, such as identifying gaps in care based on treatment codes, and doing real-time monitoring and intervention via IoT devices such as fitness trackers. We’re in a different business and technology environment these days, and a recent survey by AIIM shows that a lot of people think that their business is being (or about to be) disrupted, and digital transformation is and important part of dealing with that. However, very few of them are more than a bit of the way towards their 2020 goals for transformation. In other words, people get that this is important, but just aren’t able to change as fast as is required. Mancini attributed this in part to the escalating complexity and chaos that we see in information management, where — like Alice — we are running hard just to stay in place. Given the increasing transparency of organizations’ operations, either voluntarily or through online customer opinions, staying in the same place isn’t good enough. One contributor to this is the number of content management systems that the average organization has (hint: it’s more than one) plus all of the other places where data and content reside, forcing workers to have to scramble around looking for information. Most companies don’t want to have a single monolithic source of content, but do want a federated way to find things when they need it: in part, this fits in with the relabelling of enterprise content management (ECM) as “Content Services” (Gartner’s term) or “Intelligent Information Managment” (AIIM’s term), although I feel that’s a bit of unnecessary hand-waving that just distracts from the real issues of how companies deal with their content.
We’re in a different business and technology environment these days, and a recent survey by AIIM shows that a lot of people think that their business is being (or about to be) disrupted, and digital transformation is and important part of dealing with that. However, very few of them are more than a bit of the way towards their 2020 goals for transformation. In other words, people get that this is important, but just aren’t able to change as fast as is required. Mancini attributed this in part to the escalating complexity and chaos that we see in information management, where — like Alice — we are running hard just to stay in place. Given the increasing transparency of organizations’ operations, either voluntarily or through online customer opinions, staying in the same place isn’t good enough. One contributor to this is the number of content management systems that the average organization has (hint: it’s more than one) plus all of the other places where data and content reside, forcing workers to have to scramble around looking for information. Most companies don’t want to have a single monolithic source of content, but do want a federated way to find things when they need it: in part, this fits in with the relabelling of enterprise content management (ECM) as “Content Services” (Gartner’s term) or “Intelligent Information Managment” (AIIM’s term), although I feel that’s a bit of unnecessary hand-waving that just distracts from the real issues of how companies deal with their content.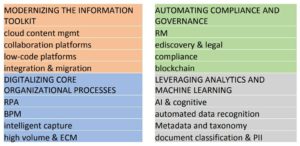 He went through some other key findings from their report on what technologies that companies are looking at, and what priority that they’re giving them; looks like it’s worth a read. He wrapped up with a few of his own opinions, including the challenge that we need to consider content AND data, not content OR data: the distinction between structure and unstructured information is breaking down, in part because of the nature of natively-digital content and in part because of AI technologies that quickly turn what we think of as content into data.
He went through some other key findings from their report on what technologies that companies are looking at, and what priority that they’re giving them; looks like it’s worth a read. He wrapped up with a few of his own opinions, including the challenge that we need to consider content AND data, not content OR data: the distinction between structure and unstructured information is breaking down, in part because of the nature of natively-digital content and in part because of AI technologies that quickly turn what we think of as content into data.