A few weeks ago, I had the chance to see Fujitsu’s new process discovery product/service in action. Unlike the usual sort of process discovery, which involves business analysts running around and documenting what people are doing, this automates the discovery of business processes by examining logs of existing applications.
The problem with the manual process discovery — based on observation, interview and operations/procedures manuals — is that it’s very labor-intensive, and can produce inaccurate results. The inaccuracies can be due to the level of experience of the business analysts, as well as what Michael zur Muehlen refers to as “process confabulation”: when you ask someone about what they do and they don’t have a good answer, they’re just as likely to make something up as they are to admit that they don’t know. I’ve seen this a lot, and tend to base most of what I do in process discovery on observation rather than interviews so that I can see the actual process; my ears perk up when I hear “well, we’re supposed to do it this way, but this is what we actually do”.
In a lot of cases, information about the business processes that are actually executed is embodied within existing enterprise applications, and saved to databases and log files. These could be supply chain, ERP, databases, legacy transactional systems or any other system that records events in some fashion. It is possible to install measurement tools on these systems to track what’s happening, or modify these systems to emit events, but Fujitsu’s new process discovery product/service extracts events from existing database and logs without modifications to existing systems. The real magic, however, comes in the software that Fujitsu has created to visualize those events in the context of a business process, and separate the “happy path” from the exceptions. Once that’s done, it’s possible to look at the ways to reduce exceptions, since the events that cause those exceptions are well understood.
I use the term “product/service” since all this manipulation and analysis requires some amount of training, and Fujitsu currently offers it as a consulting service, although there are standard software portions involved as part of that service. They have three levels of service, ranging from a basic extraction and visualization, to a more comprehensive analysis, to a customized offering. They’ve been using this with customers in Japan for some time — hence the Japanese case studies — and have recently launched their North American trial. Furthermore, it’s not specific to Fujitsu Interstage customers: this is really an independent effort of looking at your existing systems and optimizing your business processes. If that led to you buying Interstage, they’d be thrilled, but it’s not a prerequisite.
Looking at the new toys is the fun part of my job, so Keith Swenson took me for a test drive of the visualization tool. We were looking at a map of the events extracted from database logs for about 5,000 process instances, which were read into the process viewer using a standard CSV import. The straight-through path is detected and shown — in this case, it came from 632 process instances — but a slider control allowed us to change the threshold and add in more of the instances, up to 100% (which showed a pretty complex mess of a process).



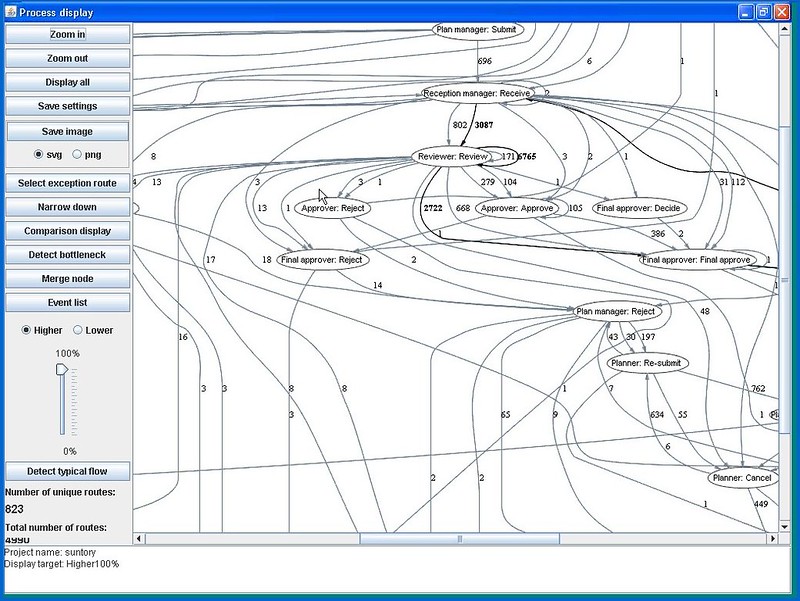
That’s a pretty cool visualization, since the exception paths appear dynamically as the slider moves, but you really want to pick a simple baseline version of the process using the slider control — not the trimmed-down straight-through path, but one that includes the most common routes — then select one or more exception paths to overlay on it. Exception paths can be sorted and filtered for selection, using criteria including frequency, deviation, repetition, backtracks, and specific transitions.
Visually, the straight-through path shows as a thick black line, the alternative routes as gray lines, and the selected exception paths are in red. Although the number beside the black lines indicate the number of process instances that traveled that path, we figured out that the number beside the red (exception) lines indicated the step in the process sequence, since that’s more relevant when you’re tracking exceptions. Other information about transition times can also be shown, indicating bottlenecks in the process.
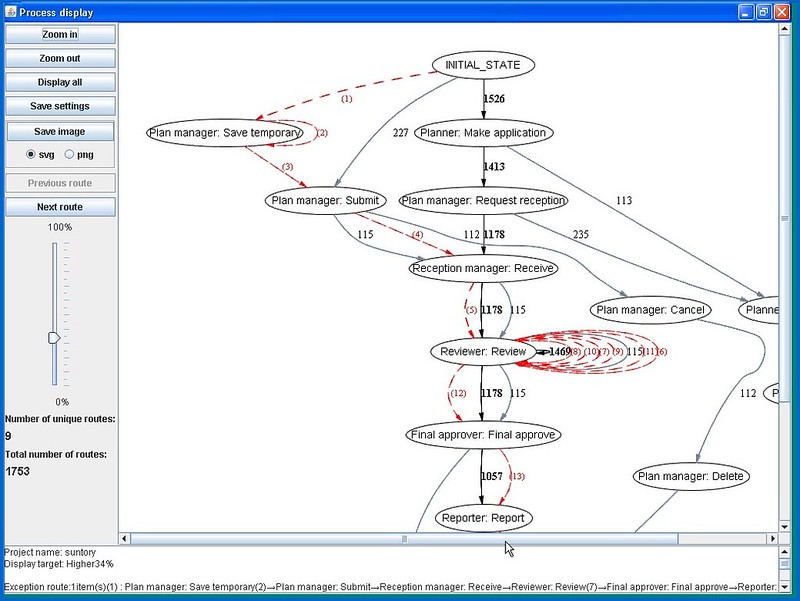
The tool is intended to be used interactively by a knowledgeable analyst in order to guide the views that will highlight the trouble spots: sort of like using simulation with real data. This isn’t an automated tool that takes data in one end and spits out the answers at the other; it’s meant to drive discussion and analysis, not replace it.

Keith showed me the results of three other case studies, and a couple of interesting effects of the data visualization and analysis that would make a quality manager’s heart sing:
- In a hard drive manufacturing plant, the assembly portion of the process was simple, but the pre-process and test lines were much more complex. Eliminating the exception routes to improve the process actually had the effect of improving the quality of the drives being manufactured on the line.
- In the second case, the processes of two different branch offices were compared, and it was identified that in one, half of the orders that their customers placed were for items that were not in stock, whereas the other office shipped most of their orders from their existing stock. There was no judgement about which was better, but it’s useful to be able to identify that one is using a just-in-time approach to reduce inventory costs, whereas the other is focused on reducing time to ship.
- The third case showed some time analysis of processes to see the degree of deviation in the transition time between two steps. This is a classic statistical analysis, where a larger deviation (usually) indicates a higher potential for process improvement.
Typical benefits that their customers have seen so far are to identify and optimize inefficient processes, identify exceptions and infrequent paths, visualize the gap between the expected and actual processes, identify location-specific differences, and locate process bottlenecks.
This doesn’t, of course, consider all of the purely manual processes that are not captured in system logs, but would greatly reduce the amount of work required to map out the processes that do touch these systems in some way. Furthermore, it happens with little or no time investment from business people and analysts, hence has less impact on the customer than other discovery and analysis techniques. The reality is that this would work great in combination with some skilled manual discovery; maybe Lombardi should use this as part of their process discovery service offerings 🙂
