To finish up my trilogy of posts on legacy integration, I had a look at the Metastorm Integration Manager (MIM), which takes a very different approach from that of OpenSpan. This is based on a look at the product that I did a couple of months ago, and now that Metastorm’s back in the news with a planned IPO, it seemed like the right time.
A lot of what’s in MIM is rooted in the CommerceQuest acquisition of a few years back. In a nutshell, it leverages IBM WebSphere MQ (what we old timers refer to as “MQSeries”) to provide a process-centric, services-oriented ESB-style architecture for integrating systems, both for batch/file transfer and real-time integration, on multiple platforms.
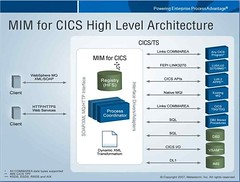 Like OpenSpan, the idea is to create web services interfaces or non-SOAP APIs around legacy applications, but instead of wrapping the user interface and running on the client, MIM wraps the apps on the server/host side and stores the resultant services in a registry. If you have CICS applications, MIM for CICS runs natively in the CICS environment and service-enables those apps, as well as allowing access to DB2 databases, VSAM and other application types. The real focus is to allow the creation of web services for custom legacy systems; packaged enterprise applications (e.g., SAP) already have their own web services interface or there’s a well-developed market of vendors already providing them.
Like OpenSpan, the idea is to create web services interfaces or non-SOAP APIs around legacy applications, but instead of wrapping the user interface and running on the client, MIM wraps the apps on the server/host side and stores the resultant services in a registry. If you have CICS applications, MIM for CICS runs natively in the CICS environment and service-enables those apps, as well as allowing access to DB2 databases, VSAM and other application types. The real focus is to allow the creation of web services for custom legacy systems; packaged enterprise applications (e.g., SAP) already have their own web services interface or there’s a well-developed market of vendors already providing them.
Although Metastorm’s BPM has some native integration capability, MIM is there to go beyond the usual email, web services and database integration, especially for mainframe integration. Metastorm BPM can call the message-driven micro-flows or web services created by MIM in order to invoke functionality on the legacy systems and return the results to the BPM process.
I saw a demo of how to create a service to access a VSAM data set, which took no more than 5 minutes: through the MIM Eclipse-based IDE, you access CICS registry, create a new VSAM service, import the record definition from the COBOL copybook for the particular VSAM file, and optionally create metadata definitions to rename ugly field names. Saving the definition generates the WSDL and makes it immediately available, with standard methods for VSAM access created by default.
They also showed how to create a service orchestration process flow — an orchestrated set of service calls that could call any of the services in the MIM registry, including invoking batch jobs and managing FTP. With MIM for CICS, everything in a micro-flow is tracked through its auditing subsystem in CICS, even if it calls services that are not in CICS; the process auditing is very detailed, allowing drilldowns into each step to show what was called when, and what data was passed.
Once created, service definitions can be deployed on any platform that MIM supports (Windows, Z-series, i-series, UNIX), and moved between platforms transparently.
 We spent a bit of time looking at file transfer, which is still a big part of the integration market and isn’t addressed by messaging. MIM provides a way to control the file transfer in an auditable way, using MQ as the backbone and breaking the file into messages. This actually outperforms FTP, allows for many-to-many transfers more effectively due to the inherent overhead (chattiness) in each FTP transfer, and allows for file-to-message transfers and vice versa, e.g., file creation from message driven by SQL statement.
We spent a bit of time looking at file transfer, which is still a big part of the integration market and isn’t addressed by messaging. MIM provides a way to control the file transfer in an auditable way, using MQ as the backbone and breaking the file into messages. This actually outperforms FTP, allows for many-to-many transfers more effectively due to the inherent overhead (chattiness) in each FTP transfer, and allows for file-to-message transfers and vice versa, e.g., file creation from message driven by SQL statement.
A directory monitor watches for inbound files and triggers actions based on file names, extensions and/or contents. A translator such as Mercator or TIBCO might be called to transform data, and the output written to multiple systems in different formats, e.g., XML, text, messages, SQL to database, files.
MIM for CICS can also drive 3270 green screens in order to extract data, using tools in the design environment to build screen navigation. This runs natively inside CICS, not on a client workstation, so is more efficient and secure than the usual screen-scraping applications.
In addition to all this, MIM can invoke any program on any platform that it supports, feed information to stdin, and capture output from stdout and stderr in the MIM auditing subsystem.
 On its own, this is a pretty powerful set of integration tools for service-enabling legacy applications, both batch and real-time, but they’ve also integrated this into Metastorm BPM. Of course, any service that you define in MIM can be called from any system that can invoke a web service — which includes all BPM systems — but MIM can launch a Metastorm human-facing process for exception handling from within one of its service orchestration processes by passing a MIM exception to the BPM server. The BPM process can pass it back to MIM at a point in the process if that’s allowed, for example if the user corrects data that will allow the orchestration to proceed, and the BPM user may be given the option to select the step in the MIM process at which to reinject the process.
On its own, this is a pretty powerful set of integration tools for service-enabling legacy applications, both batch and real-time, but they’ve also integrated this into Metastorm BPM. Of course, any service that you define in MIM can be called from any system that can invoke a web service — which includes all BPM systems — but MIM can launch a Metastorm human-facing process for exception handling from within one of its service orchestration processes by passing a MIM exception to the BPM server. The BPM process can pass it back to MIM at a point in the process if that’s allowed, for example if the user corrects data that will allow the orchestration to proceed, and the BPM user may be given the option to select the step in the MIM process at which to reinject the process.
What happens in Metastorm BPM when it is invoked as an exception handler is not tracked in the MIM process auditor; instead, it captures the before and after of the data that’s passed to BPM, and this would need to be reconciled in some way with the analytics in BPM. This separation of processes — into those managed and audited by BPM and those managed and audited by MIM — is an area where some customers are likely to want more integration between the two products in the future. However, if you consider the services created by MIM as true black boxes from the BPM viewpoint, then there’s nothing wrong with separation at this level. It’s my understanding that MIM calls BPM using a web service call, so really any system that can be called as a web service, including most other BPMS, could be called from MIM for exception handling instead.