
I’ve had a look at Contextware previously, but yesterday had a chance to talk in depth with David Austin, the president and COO, and see a demo of their current product. Contextware can be described as a a process documentation tool, although it’s also being used as a process discovery tool, but it’s more than just a static document of your operational procedures: for each step in a process, it displays a narrative that might include context or instructions, plus links to various resources including content, applications, and people. You capture processes in Contextware for the purpose of communication and training, not automation; it doesn’t automate processes in any way, but might be combined with a BPMS in order to provide instructions for complex human steps in the process.
There a couple of key use cases for this sort of process documentation, whether you’re doing it for completely manual processes or for the human steps in a BPMS:
- You need to capture information from those aging boomer knowledge workers (who will be retiring as soon as the stock market comes back up), since many of the manual processes exist only in their heads.
- You want to standardize processes across the organization, and need to provide operational procedures documentation for those processes.
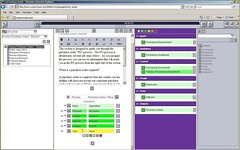 There is no automated capture of information: you have to lay the process out step by step, but it’s done in a simple hierarchical list format where you create a list of the main steps, then can add sub-steps to any step as an indented sub-list, and so on. Then, for each step/sub-step, you add the narrative and link up the assets from the list of available resources. Assets linked to a step are inherited by its sub-steps, and can be kept, discarded or a subtype created during the authoring process.
There is no automated capture of information: you have to lay the process out step by step, but it’s done in a simple hierarchical list format where you create a list of the main steps, then can add sub-steps to any step as an indented sub-list, and so on. Then, for each step/sub-step, you add the narrative and link up the assets from the list of available resources. Assets linked to a step are inherited by its sub-steps, and can be kept, discarded or a subtype created during the authoring process.
Assets can be predefined — these are in a common repository that can be reused by any process — or defined and saved to the repository on the fly. Content such as documents are typically not stored in Contextware: the asset is actually metadata pointing to external content via a URL or URI, which allows the author to set a meaningful name for the asset that is shared wherever that asset is used within any process. Although it’s common for organizations to have samples and procedural documentation online somewhere on their intranet, this removes the process of hunting for the file or page since it’s linked directly to the step in the process where it’s required.
The resources are a sort of extended IDEF model with six dimensions, and the author can suppress the display of any of them:
- Inputs (often suppressed), which may link to content or to a system depending on the context
- Guidelines: additional procedural documentation
- Content: typically samples
- People, which allows for a mailto: link to directly create an email
- Tools, providing links to invoke systems and executables, or describe offline resources or tools
- Outputs (often suppressed)
There’s no auto-login or single sign-on for any of the systems that are linked from resources (e.g., content management, email, line of business applications): these are just links to launch the appropriate application or content, and the user is responsible for doing the login themselves on the invoked application if they’re not already logged in.
I’m not sure that I completely understand the role of inputs and outputs in the resource list; it might be stretching the IDEF metaphor a bit too much (and for little purpose these days, when many people don’t know what IDEF is).
An author can clone an existing process to start a new design and there’s some lightweight versioning and roll-back capabilities for managing the processes. It’s also possible to call one process (or subprocess) from another by listing it as an asset in the resources.
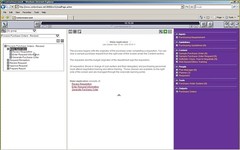 The end users select their group/department from a list, then their process, then select the step that they’re working on (or expand the step hierarchy and click on a sub-step) to see the narrative and the list of resources available. Clicking on a resource for that step in the right-hand panel will invoke the URL or URI that’s specified for the resource: it could be a link to a web page or document, an executable desktop application, or a mailto: link for a person. The text in the center panel changes depending on which step or which resource that they’ve selected. Users can also add comments to a step via a context-sensitive “bulletin board” at each step, providing a bit of a wiki-like experience to capture the users’ feedback directly in the context of the process, although they can’t change the main narrative.
The end users select their group/department from a list, then their process, then select the step that they’re working on (or expand the step hierarchy and click on a sub-step) to see the narrative and the list of resources available. Clicking on a resource for that step in the right-hand panel will invoke the URL or URI that’s specified for the resource: it could be a link to a web page or document, an executable desktop application, or a mailto: link for a person. The text in the center panel changes depending on which step or which resource that they’ve selected. Users can also add comments to a step via a context-sensitive “bulletin board” at each step, providing a bit of a wiki-like experience to capture the users’ feedback directly in the context of the process, although they can’t change the main narrative.
Users are not constrained to follow the steps in order; they can see the entire hierarchy and select any step that they need, since this is process documentation and doesn’t actually drive their work. In fact, this could be used as a contextual help system without regard to a process, organizing the help topics in the hierarchy on the left and attaching narrative and assets to each topic and subtopic.
Both authors and end users can search on processes and metadata to locate a specific process or resource.
An audit (management) function shows who has accessed which processes, which allows a manager to tell if someone has accessed a new process after it has been rolled out. Since this can be considered training material, the manager is basically checking to see if everyone did their homework and understands the new process.
Both the authoring and end-user environment are completely web-based with a rich AJAX interface, so no desktop installation. We didn’t talk about what’s lurking on the server side of this, but their website lists the operating systems, database, application servers and web servers supported. Their site also talks about delivering content to mobile devices, but we didn’t discuss that.
There’s an obvious play in the training space and for documentation of manual processes, but Contextware would also like to see how they can put this together with some of the BPMS products in order to provide additional documentation for human-facing steps in cases where it’s difficult to build that into the BPMS user interface itself. I also believe that they need to focus on importing from some of the BPA tools, such as ARIS and Mega: although the process model is only a starting point for Contextware, it would be helpful to have that starting point in the case of large complex processes with a lot of manual steps. Of course, this may start to conflict with what some of the BPA vendors are trying to do in terms of process documentation, but I think that most of them are really focused on showing the business processes rather than providing complete operational procedures. I also see potential for integration with a process discovery tool such as Process Master, although there might be too much overlap in functionality.
There needs to be much better management of screen real estate as well: this product smacks of developers with huge dual monitor setups who don’t realize that the average underwriter in an insurance company works on a single 800×600 15″ screen. I suggested that they be able to minimize to some sort of floating widget (which could be difficult considering that they’re web-based, but hey, that’s what Adobe AIR and Google Gadgets are for, right?) that the user could float their mouse over to pop up the narrative and resources, and click to the next step. Otherwise, you’d be trying to deploy this on a screen where the user has to constantly flip back and forth between Contextware as their procedural guide and their actual applications. Printing would ensue.
They also need to do a bit more with versioning of processes, where a process could be modified and tested by a specific group of people, then promoted to the production version. In the current system, you’d clone the process (and therefore have to use ad hoc naming conventions to indicate that this was a new version of the older process), make the changes, and release selectively by security groups in order to promote through test and production.  Once in production, the users of the old process would have to be notified to start using the new process documentation.
Once in production, the users of the old process would have to be notified to start using the new process documentation.
One final criticism about the cutesy interface icons: using a graphic of a sheep (think Dolly) to clone a process just doesn’t cut it for me.
Need to know that that I have 4 yrs exp. in Savvion. Would like to scope for the same.
Thank you