
Niko Vogel of AXA Germany and Matthias Schulte of their consulting partner viadee presented on AXA’s journey from a process engine that they built in-house to a Camunda cloud-based process engine. This was driven by their move to a new policy management system, with the goal to automate as much as possible of their end-to-end travel and health insurance process, and support the knowledge workers for the human tasks.
They’ve seen a huge change in how business and IT work together: collaborating over process optimization and troubleshooting, for example. They have a central team for more of the infrastructure issues such as reporting and security, as well as acting as a center of excellence for BPMN and DMN.
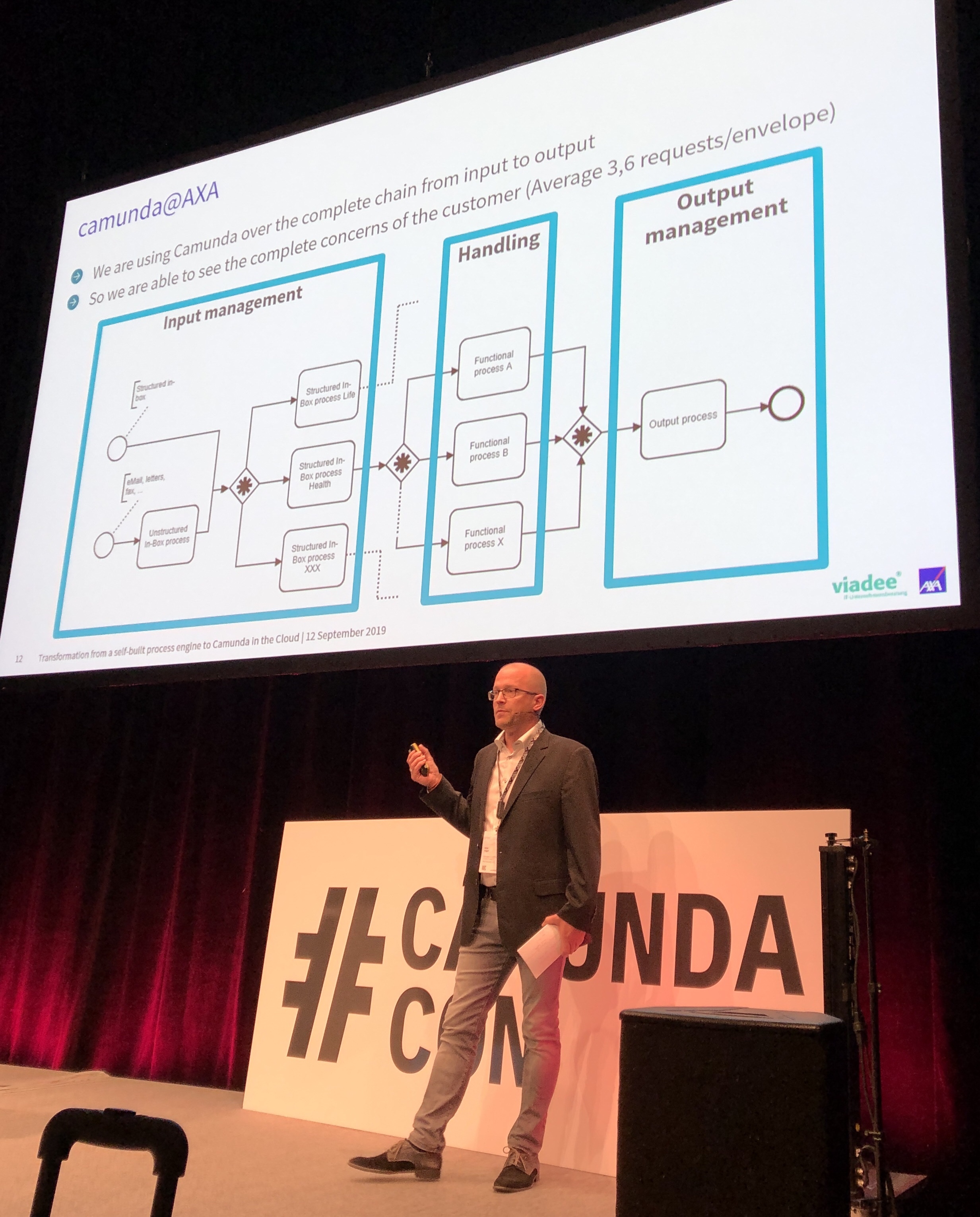
They have made some extensions to Camunda’s Cockpit dashboard to tie in more business information, allowing business users to access it directly for looking up specific policy-related processes and see what’s happening with them. They’ve also done a “DMN Manager” extension to control the modification and deployment of decision tables, although changes to decision tables can still be done by the business without involvement from IT. Another significant extension is to collect runtime statistics from Camunda and other line-of-business systems to do some analysis on the aggregate; based on something that we saw in Daniel’s keynote this morning, this capability may soon be something offered directly by Camunda.
Their architecture started as a “shared monolith” in 2017, that is, a central deployment of a single Camunda server instance used by all process applications — note that this is the primary deployment model for many BPMS. They felt this was a good first step, but moved to a decentralized Spring Boot architecture to create decentralized standalone applications, although common tools remained in a shared instance.
Now, they’re moving to the cloud, which allows reuse of their existing service access architecture (integrating with policy administration system, for example) via tunneling in a very similar way as they used with the on-premise Spring Boot implementation. The current point of discussion is about how many databases to use: they are likely to move from their current centralized database to a less centralized model. This will give them much better elastic scalability and performance — a common database is a classic chokepoint when scaling — although this will require some definite rework to determine how to split up the databases and how to handle cross-application reporting in a transparent fashion.
Good questions and discussion with the audience at the end, including managing their large process model as it moves through business-IT collaboration to deployment.