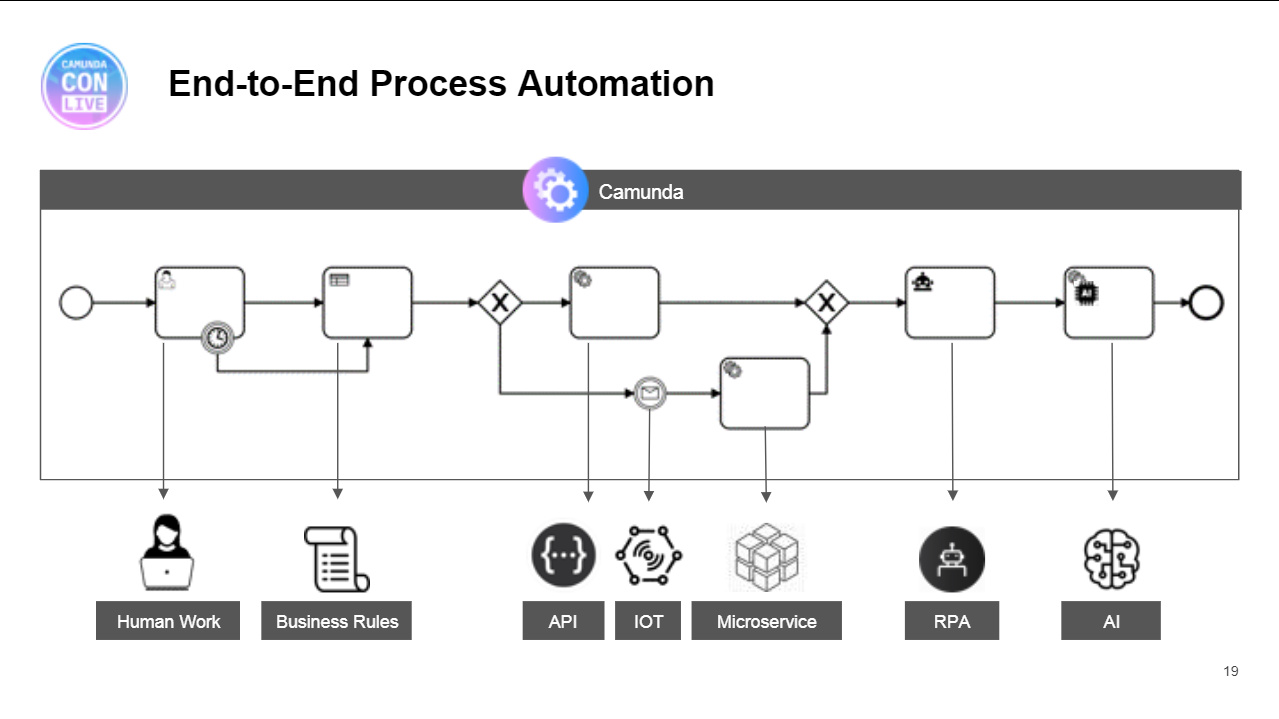
I listened to Camunda CEO Jakob Freund‘s opening keynote from the virtual CamundaCon 2020.2 (the October edition), and he really hit it out of the park. I’ve known Jakob a long time and many of our ideas are aligned, and there was so much in particular in his keynote that resonated with me. He used the phrase “reinvent [your business] or die”, whereas I’ve been using “modernize or perish”, with a focus not just on legacy systems and infrastructure, but also legacy organizational culture. Not to hijack this post with a plug for another company, but I’m doing a keynote at the virtual Bizagi Catalyst next week on aligning intelligent automation with incentives and business outcomes, which looks at issues of legacy organizational culture as well as the technology around automation. Processes are, as he pointed out, the algorithms of an organization: they touch everything and are everywhere (even if you haven’t automated them), and a lot of digital-native companies are successful precisely because they have optimized those algorithms.
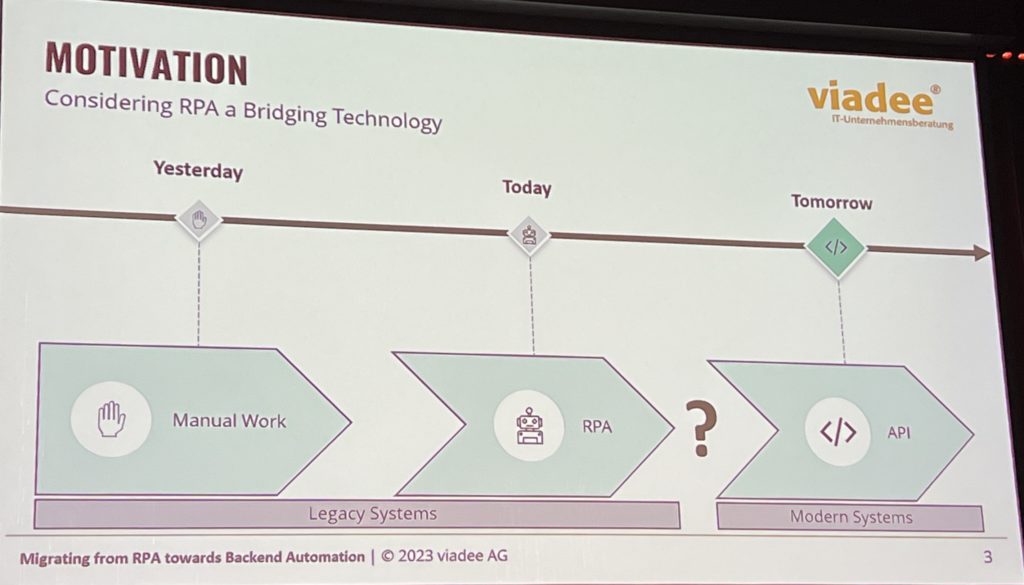
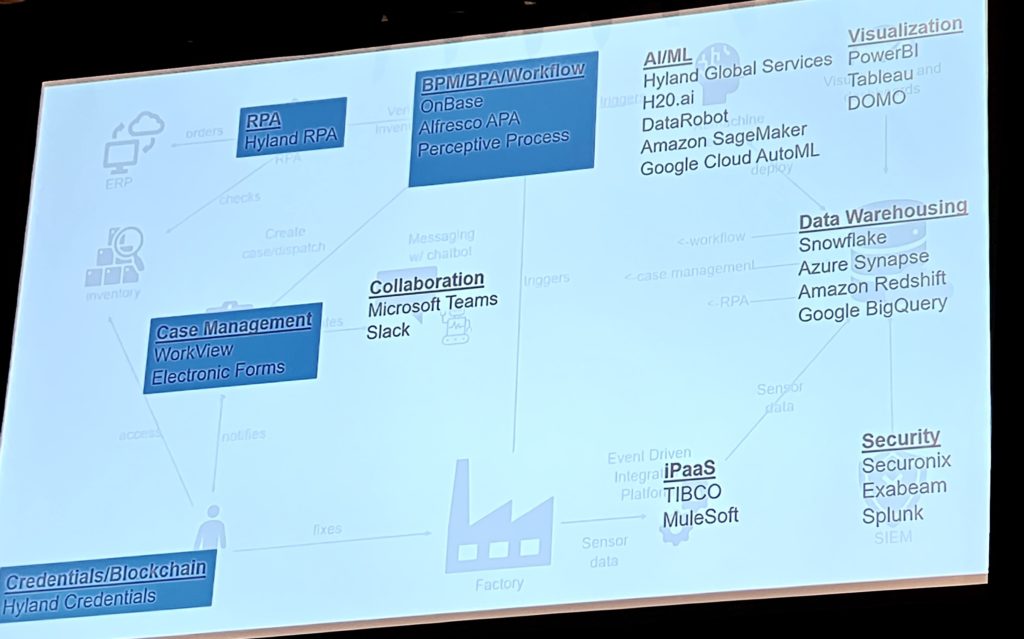
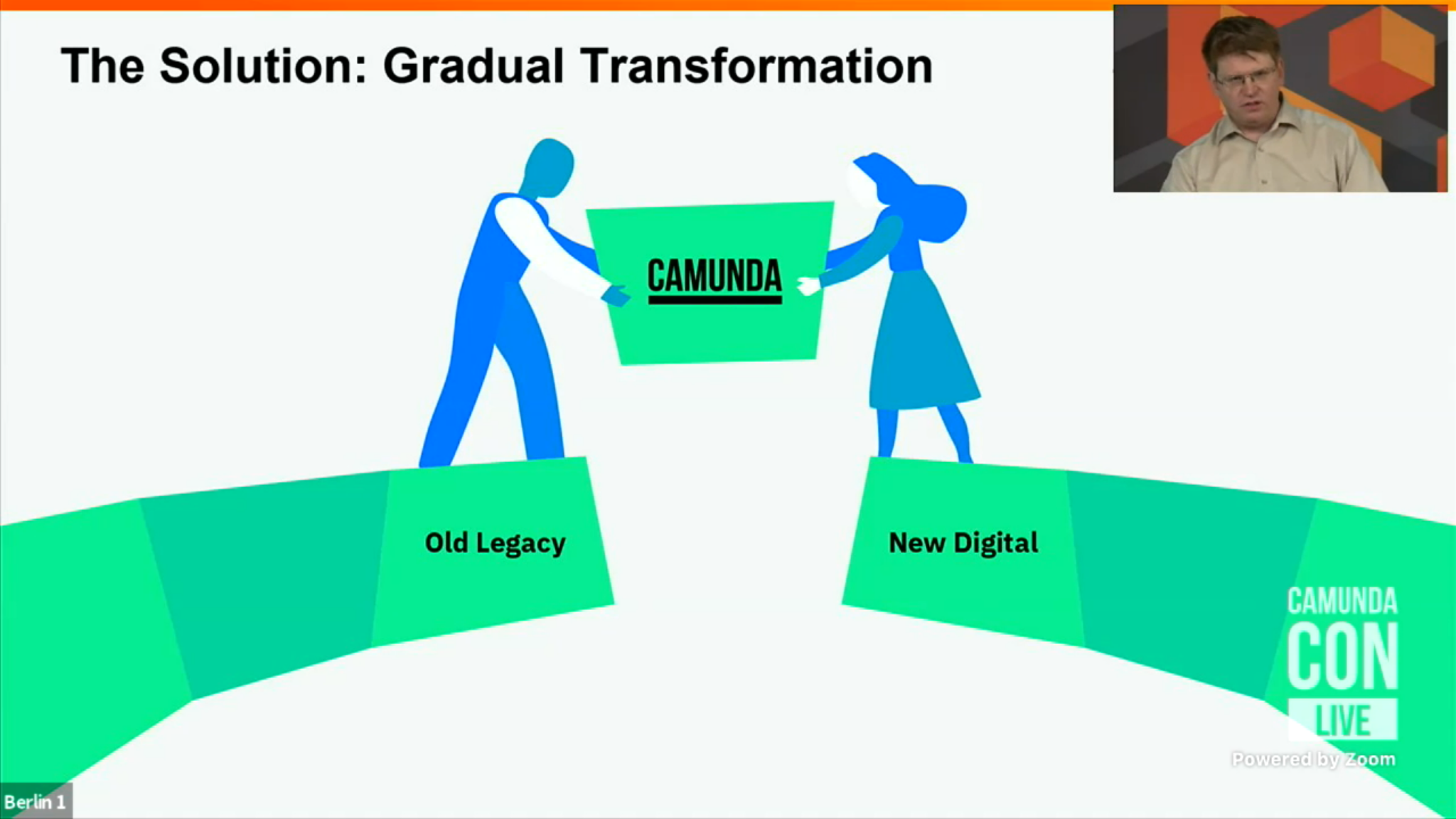
 Jakob’s advice in achieving reinvention/modernization is to do a gradual transformation, not try to do a big bang approach that fails more often than it succeeds, and positions Camunda (of course) as the bridge between the worlds of legacy and new technology. In my years of technology consulting on BPM implementations, I also recommend using a gradual approach by building bridges between new and old technology, then swapping out the legacy bits as you develop or buy replacements. This is where, for example, you can use RPA to create stop-gap task automation with your existing legacy systems, then gradually replace the underlying legacy or at least create APIs to replace the RPA bots.
Jakob’s advice in achieving reinvention/modernization is to do a gradual transformation, not try to do a big bang approach that fails more often than it succeeds, and positions Camunda (of course) as the bridge between the worlds of legacy and new technology. In my years of technology consulting on BPM implementations, I also recommend using a gradual approach by building bridges between new and old technology, then swapping out the legacy bits as you develop or buy replacements. This is where, for example, you can use RPA to create stop-gap task automation with your existing legacy systems, then gradually replace the underlying legacy or at least create APIs to replace the RPA bots.
The second opening keynote was with Marco Einacker and Christoph Anzer of Deutsche Telekom, discussing how they are using process and task automation by combining Camunda for the process layer and RPA at the task layer. They started out with using RPA for automating tasks and processes, ending up with more than 3,000 bots and an estimated €93 million in savings. It was a very decentralized approach, with initially being created by business areas without IT involvement, but as they scaled up, they started to look for ways to centralize some of the ideas and technology. First was to identify the most important tasks to start with, namely those that were true pain points in the business (Einacker used the phrase ” look for the shittiest, most painful process and start there”) not just the easy copy-paste applications. They also looked at how other smart technologies, such as OCR and AI, could be integrated to create completely unattended bots that add significant value.
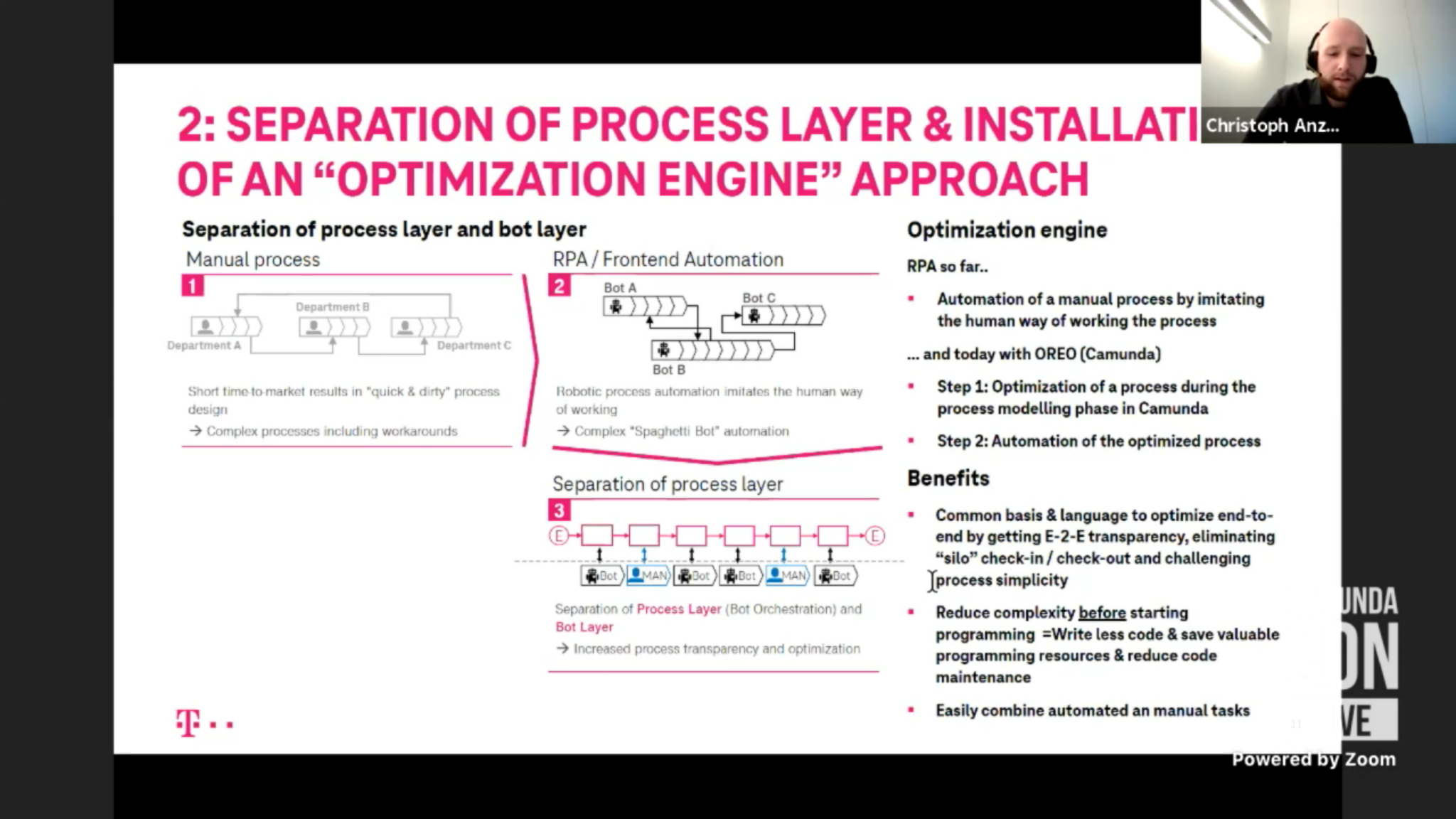
 The decentralized approach resulted in seven different RPA platforms and too much process automation happening in the RPA layer, which increased the amount of technical debt, so they adapted their strategy to consolidate RPA platforms and separate the process layer from the bot layer. In short, they are now using Camunda for process orchestration, and the RPA bots have become tasks that are orchestrated by the process engine. Gradually, they are (or will be) replacing the RPA bots with APIs, which moves the integration from front-end to back-end, making it more robust with less maintenance.
The decentralized approach resulted in seven different RPA platforms and too much process automation happening in the RPA layer, which increased the amount of technical debt, so they adapted their strategy to consolidate RPA platforms and separate the process layer from the bot layer. In short, they are now using Camunda for process orchestration, and the RPA bots have become tasks that are orchestrated by the process engine. Gradually, they are (or will be) replacing the RPA bots with APIs, which moves the integration from front-end to back-end, making it more robust with less maintenance.
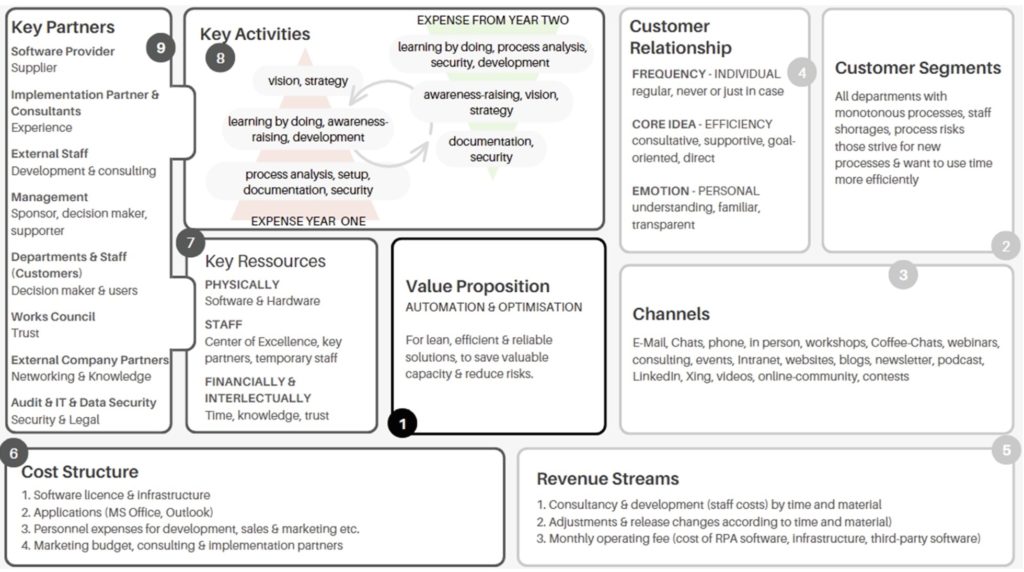
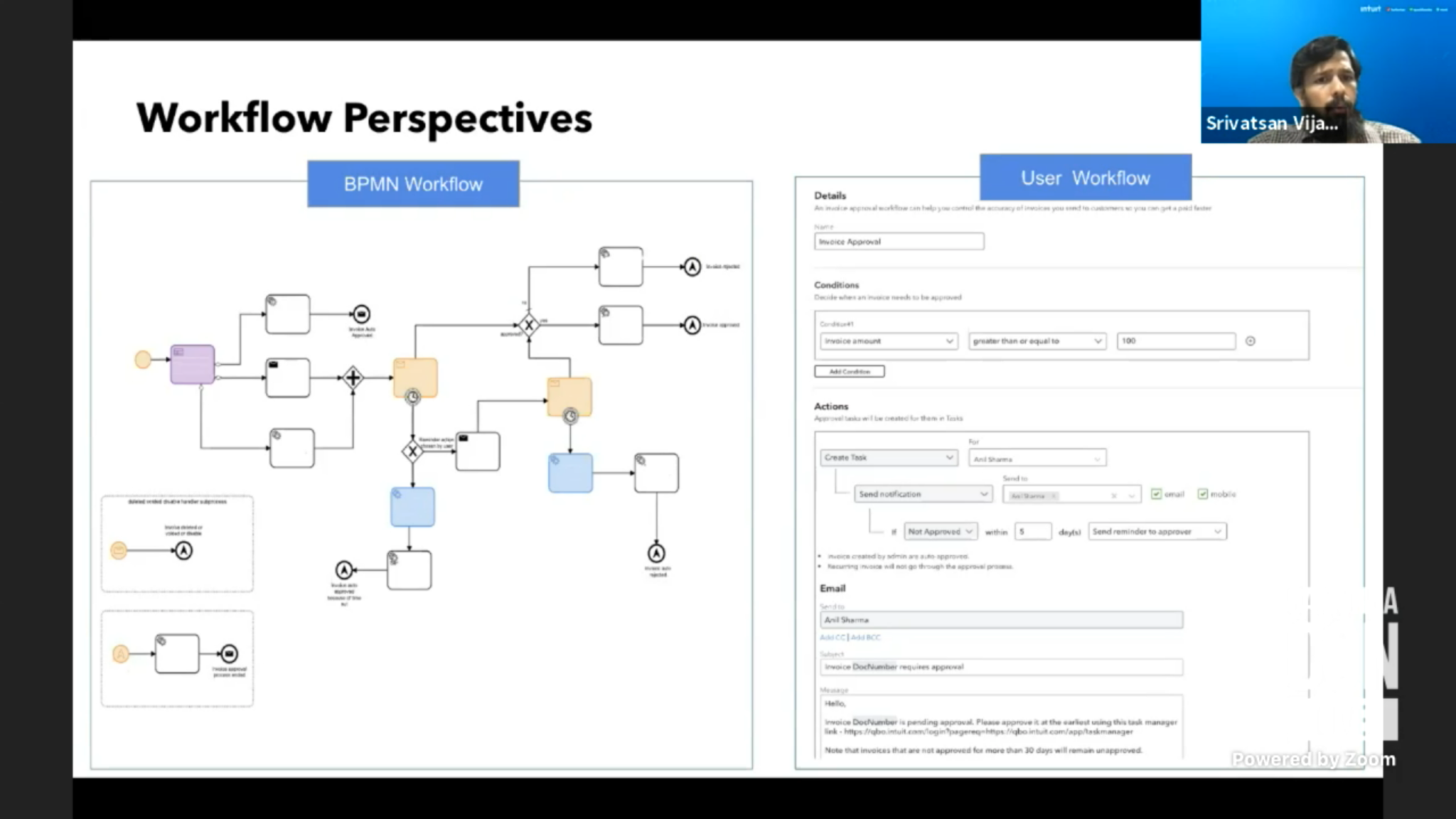
I moved off to the business architecture track for a presentation by Srivatsan Vijayaraghavan of Intuit, where they are using Camunda for three different use cases: their own internal processes, some customer-facing processes for interacting with Intuit, and — most interesting to me — enabling their customers to create their own workflows across different applications. Their QuickBooks customers are primarily small and mid-sized business that don’t have the skills to set up their own BPM system (although arguably they could use one of the many low-code process automation platforms to do at least part of this), which opened the opportunity for Intuit to offer a workflow solution based on Camunda but customizable by the individual customer organizations. Invoice approvals was an obvious place to start, since Accounts Payable is a problem area in many companies, then they expanded to other approval types and integration with non-Intuit apps such as e-signature and CRM. Customers can even build their own workflows: a true workflow as a service model, with pre-built templates for common workflows, integration with all Intuit services, and a simplified workflow designer.
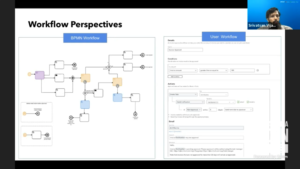 Intuit customers don’t interact directly with Camunda services; Camunda is a separately hosted and abstracted service, and they’ve used Kafka messages and external task patterns to create the cut-out layer. They’ve created a wrapper around the modeling tools, so that customers use a simplified workflow designer instead of the BPMN designer to configure the process templates. There is an issue with a proliferation of process definitions as each customer creates their own version of, for example, an invoice approval workflow — he mentioned 70,000 process definitions — and they will likely need to do some sort of automated cleanup as the platform matures. Really interesting use case, and one that could be used by large companies that want their internal customers to be able to create/customize their own workflows.
Intuit customers don’t interact directly with Camunda services; Camunda is a separately hosted and abstracted service, and they’ve used Kafka messages and external task patterns to create the cut-out layer. They’ve created a wrapper around the modeling tools, so that customers use a simplified workflow designer instead of the BPMN designer to configure the process templates. There is an issue with a proliferation of process definitions as each customer creates their own version of, for example, an invoice approval workflow — he mentioned 70,000 process definitions — and they will likely need to do some sort of automated cleanup as the platform matures. Really interesting use case, and one that could be used by large companies that want their internal customers to be able to create/customize their own workflows.
The next presentation was by Stephen Donovan of Fidelity Investments and James Watson of Doculabs. I worked with Fidelity in 2018-19 to help create the architecture for their digital automation platform (in my other life, I’m a technical architecture/strategy consultant); it appears that they’re not up and running with anything yet, but they have been engaging the business units on thinking about digital transformation and how the features of the new Camunda-based platform can be leveraged when the time comes to migrate applications from their legacy workflow platform. This doesn’t seem to have advanced much since they talked about it at the April CamundaCon, although Donovan had more detailed insights into how they are doing this.
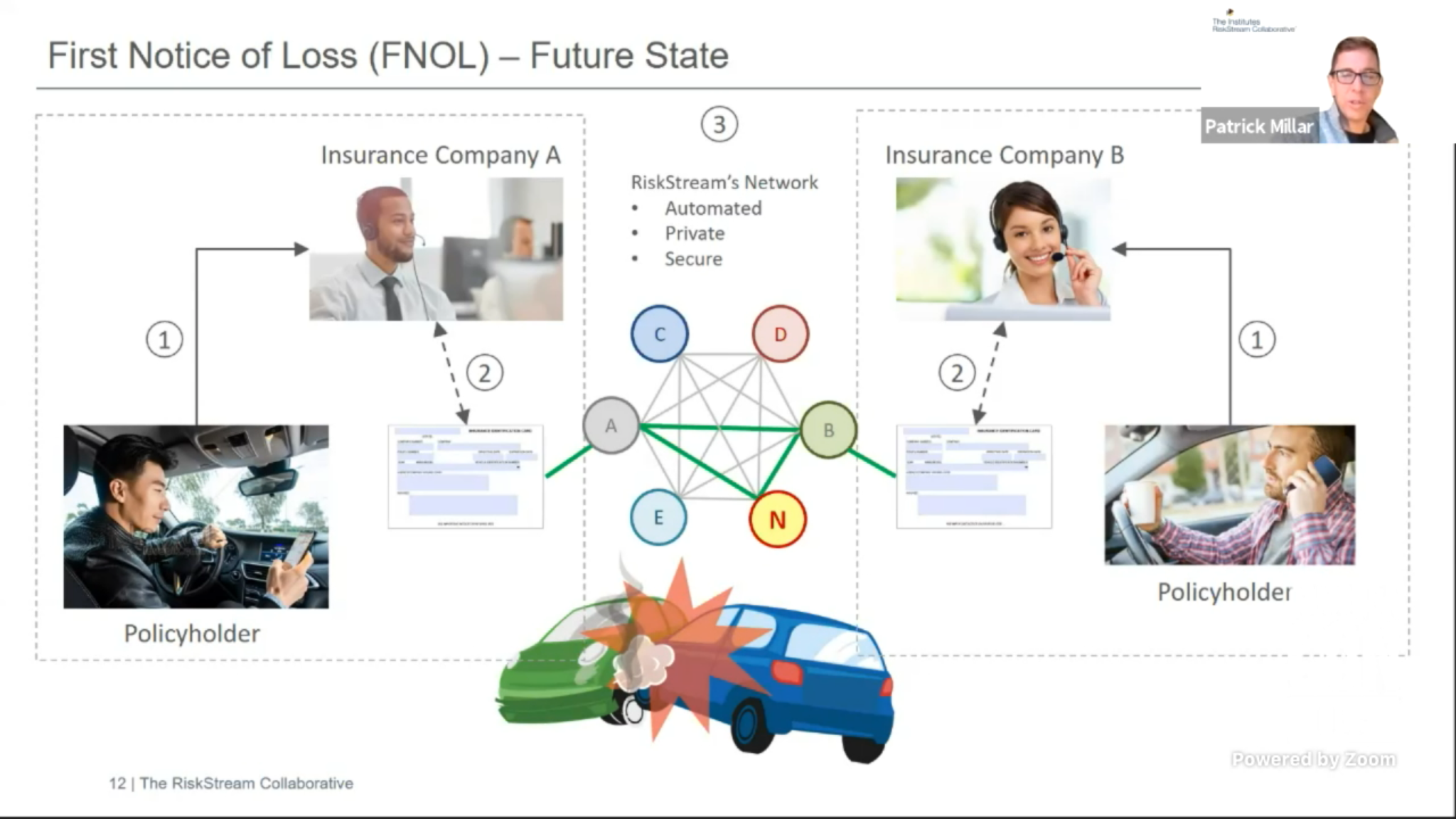
At the April CamundaCon, I watched Patrick Millar’s presentation on using Camunda for blockchain ledger automation, or rather I watched part of it: his internet died partway through and I missed the part about how they are using Camunda, so I’m back to see it now. The RiskStream Collaborative is a not-for-profit consortium collaborating on the use of blockchain in the insurance industry; their parent organization, The Institutes, provides risk management and insurance education and is guided by senior executives from the property and casualty industry.  To copy from my original post, RiskStream is creating a distributed network platform, called Canopy, that allows their insurance company members to share data privately and securely, and participate in shared business processes. Whenever you have multiple insurance companies in an insurance process, like a claim for a multi-vehicle accident, having shared business processes — such as first notice of loss and proof of insurance — between the multiple insurers means that claims can be settled quicker and at a much lower cost.
To copy from my original post, RiskStream is creating a distributed network platform, called Canopy, that allows their insurance company members to share data privately and securely, and participate in shared business processes. Whenever you have multiple insurance companies in an insurance process, like a claim for a multi-vehicle accident, having shared business processes — such as first notice of loss and proof of insurance — between the multiple insurers means that claims can be settled quicker and at a much lower cost.
 I do a lot of work with insurance companies, as well as with BPM vendors to help them understand insurance operations, and this really resonates: the FNOL (first notice of loss) process for multi-party claims continues to be a problem in almost every company, and using enterprise blockchain to facilitate interactions between the multiple insurers makes a lot of sense. Note that they are not creating or replacing claims systems in any way; rather, they are connecting the multiple insurance companies, who would then integrate Canopy to their internal claims systems such as Guidewire.
I do a lot of work with insurance companies, as well as with BPM vendors to help them understand insurance operations, and this really resonates: the FNOL (first notice of loss) process for multi-party claims continues to be a problem in almost every company, and using enterprise blockchain to facilitate interactions between the multiple insurers makes a lot of sense. Note that they are not creating or replacing claims systems in any way; rather, they are connecting the multiple insurance companies, who would then integrate Canopy to their internal claims systems such as Guidewire.

Camunda is used in the control framework layer of Canopy to manage the flows within the applications, such as the FNOL application. The control framework is just one slice of the platform: there’s the core distributed ledger layer below that, where the blockchain data is persisted, and an integration layer above it to integrate with insurers’ claims systems as well as the identity and authorization registry.
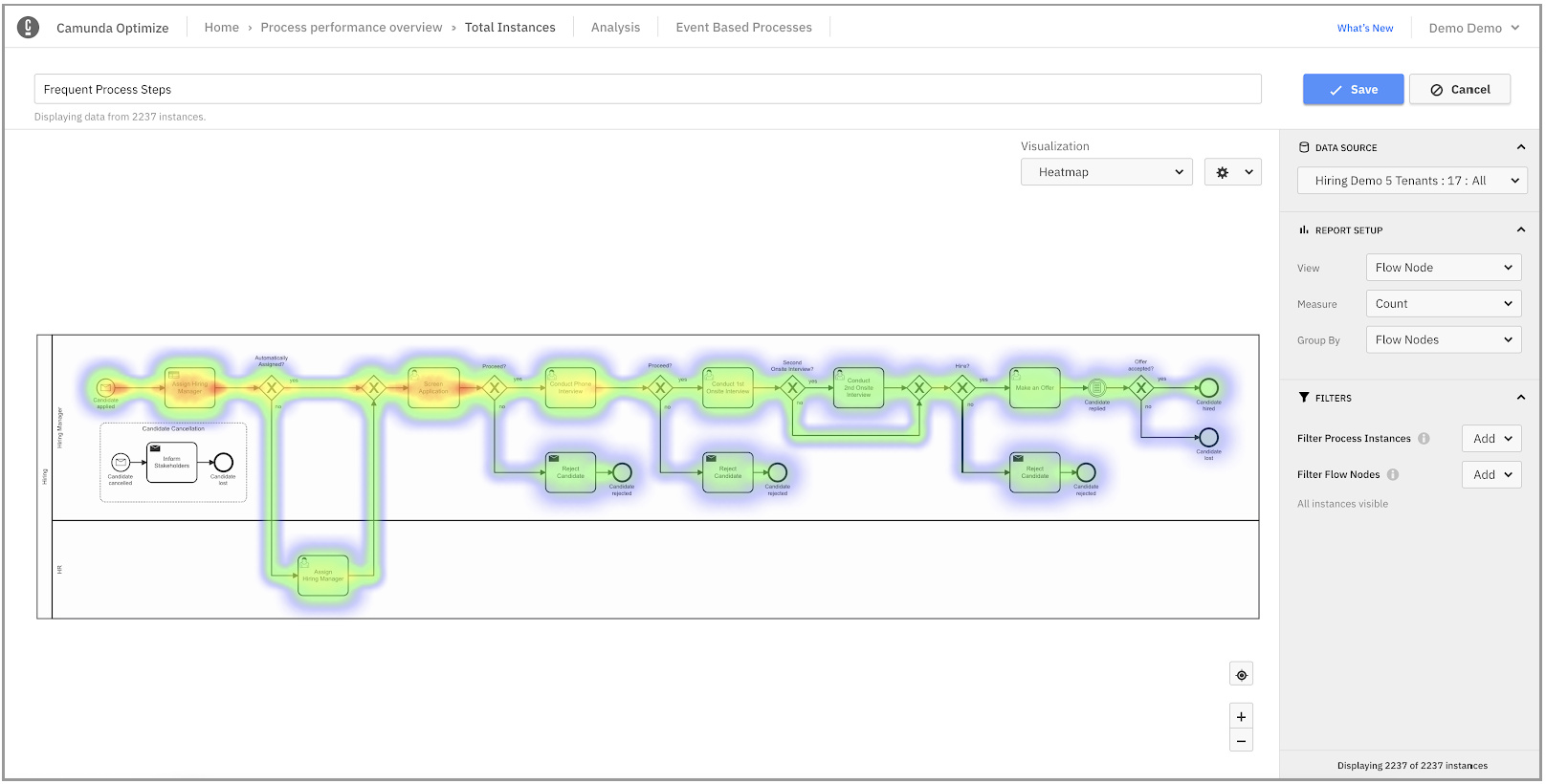
There was a Gartner keynote, which gave me an opportunity to tidy up the writing and images for the rest of this post, then I tuned back in for Niall Deehan’s session on Camunda Hackdays over on the community tech track, and some of the interesting creations that come out of the recent virtual version. This drives home the point that Camunda is, at its heart, open source software that relies on a community of developer both within and outside Camunda to extend and enhance the core product. The examples presented here were all done by Camunda employees, although many of them are not part of the development team, but come from areas such as customer-facing consulting. These were pretty quick demos so I won’t go into detail, but here are the projects on Github:
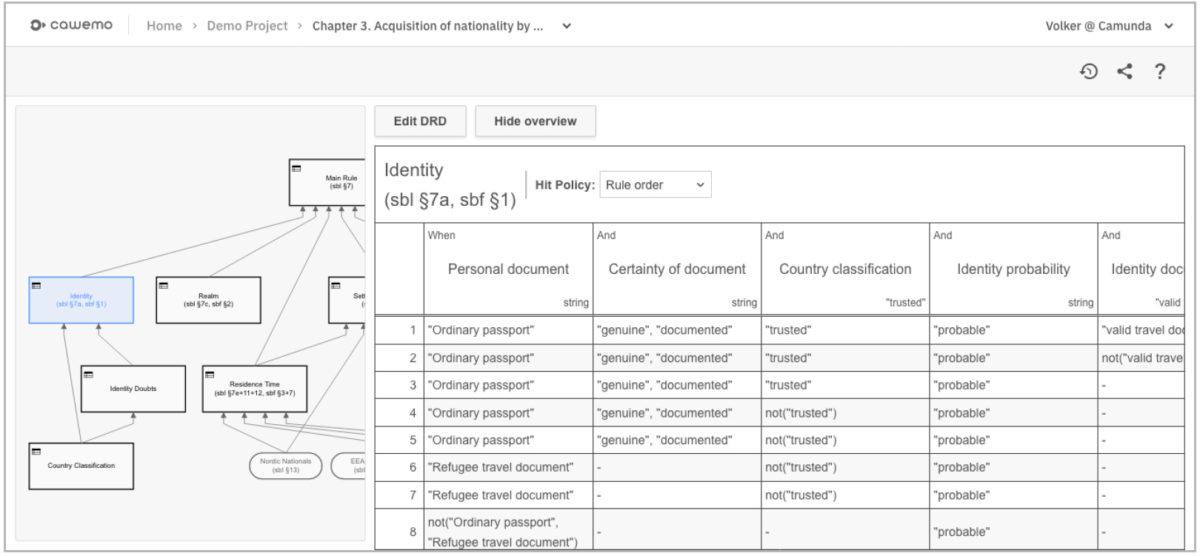
- DMN testing plugin, for testing DRD diagrams, by Stefan Wiese, Max Trumpf and Maciej Barelkowski
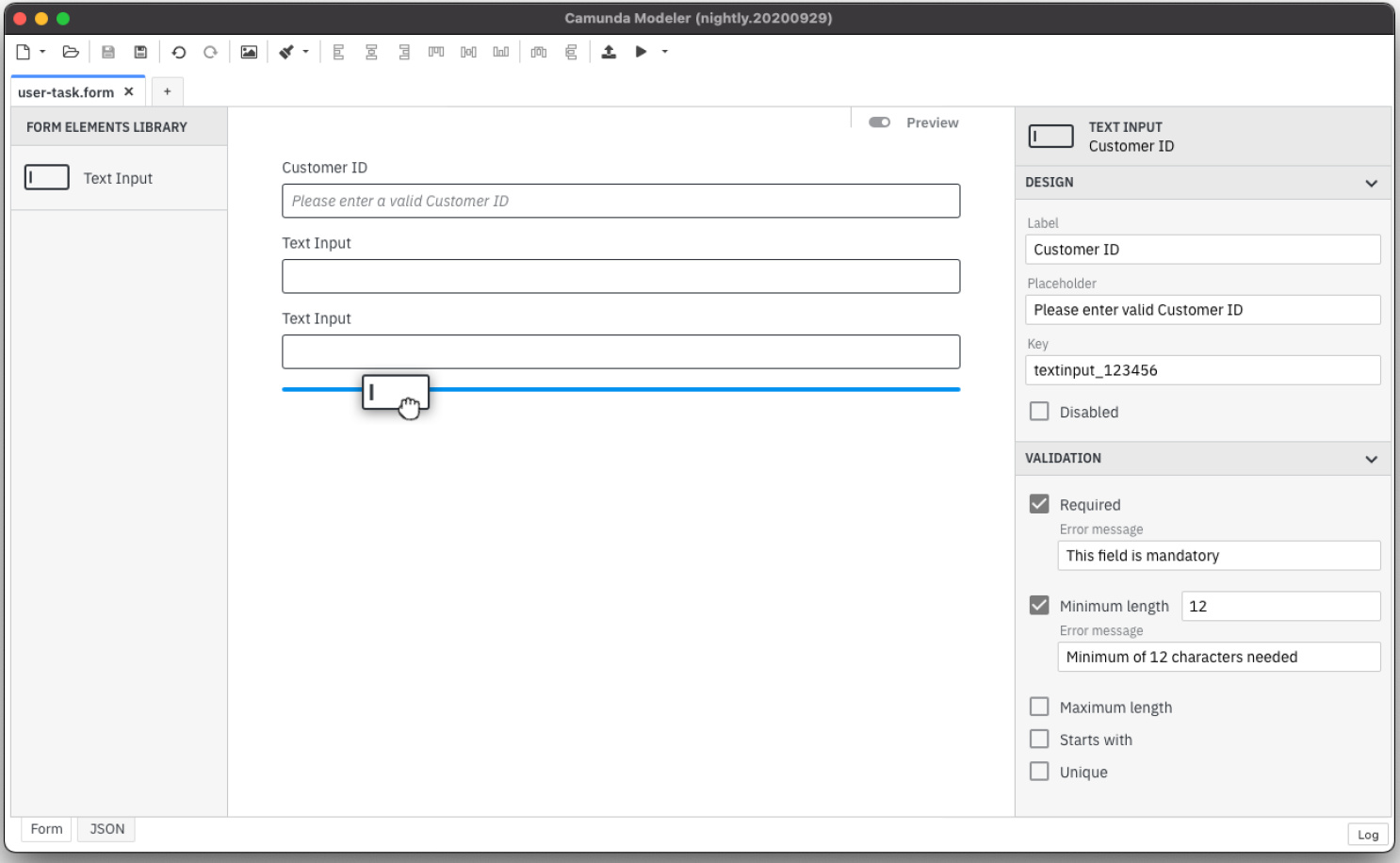
- Camunda modeler Excel import plugin, to import Excel sheets to DMN decision tables, by Felix Anhalt and Niklas Kiefer
- Deployment descriptor editor, for getting/setting running server configuration settings, by Chris Allen and Andreas Remdt
- CamundaCloud Twitter raffle, to demonstrate 3rd party API integration and microservices, by Leonhardt Wille, Lars Lange and Sebastian Bathke
If you’re a Camunda customer (open source or commercial) and you like one of these ideas, head on over to the related github page and star it to show your interest.
There was a closing keynote by Capgemini; like the Gartner keynote, I felt that it wasn’t a great fit for the audience, but those are my only real criticisms of the conference so far.
Jakob Freund came back for a conversation with Mary Thengvall to recap the day. If you want to see the recorded videos of the live sessions, head over to the agenda page and click on Watch Now for any session.
There’s a lot of great stuff on the agenda for tomorrow, including CTO Daniel Meyer talking about their new RPA orchestration capabilities, and I’ll be back for that.